

DeepSeek开源周收官:V3/R1推理系统揭秘,理论成本利润率高达545%
DeepSeek开源周结束了,DeepSeek再次用最后的炸弹在AI世界中引起了涟漪。
3月1日,DeepSeek在Zhihu上发表了一篇题为“ DeepSeek-V3/R1推理系统概述”的文章,充分揭示了V3/R1推理系统背后的关键秘密。

最值得注意的是,该文章首次披露了诸如DeepSeek的理论成本和利润率之类的关键信息。据报道,假设GPU租金成本为2美元/小时,总成本为87,072美元;如果所有令牌是根据DeepSeek R1的定价计算的,则每天的理论总收入为每天562,027美元,成本利润率为545%。
最大程度地优化推理系统,理论成本利润率高达545%
根据文章,DeepSeek-V3/R1推理系统的优化目标是更大的吞吐量和较低的延迟。为了实现这两个目标,DeepSeek使用大规模的跨节点专家并行性(专家平行性/EP)方法,并使用一系列技术策略来最大程度地优化大型模型推理系统,从而实现惊人的性能和效率。

具体而言,就较大的吞吐量而言,大规模的跨节点专家并行性可以大大增加批量的大小(批量大小),从而提高了GPU矩阵乘法的效率并改善了吞吐量。
批量大小是深度学习中非常重要的超参数,指培训期间每次使用该模型的数据量。它确定每次更新模型时使用的培训样本的数量。调整批处理大小会影响模型的训练速度,内存消耗以及模型重量的更新方式。
在较低的延迟方面,大规模的跨节点专家并行的专家可以分布在不同的GPU中,每个GPU都需要计算较少的专家(因此内存提取要求更少),从而减少延迟。
但是,由于大规模的跨节点专家并行性将大大提高系统的复杂性,带来诸如跨节点通信,多节点数据并行性和负载平衡等挑战,因此DeepSeek还专注于如何隐藏时间耗时的变速器以及如何在使用大规模跨节点专家时进行大规模跨节点的负载平衡以增加批量划分大小。
具体而言,DeepSeek团队主要最大化资源利用率,并通过大规模的跨节点专家并行性,双批次重叠策略,最佳负载平衡和其他方法来确保高性能和稳定性。
值得注意的是,本文还披露了诸如DeepSeek的理论成本和利润率之类的关键信息。据报道,DeepSeek V3和R1的所有服务均使用NVIDIA的H800 GPU。由于白天的服务负载较高,晚上服务负载较低,DeepSeek实施了一组机制,用于使用所有节点在白天的负载较高时使用所有节点部署推理服务。当晚上负载低时,减少用于研究和培训的推理节点。
通过时间成本控制,DeepSeek代表DeepSeek V3和R1推理服务所占据的总节点,峰值占用率为278个节点,平均为226.75个节点(每个节点为8 H800 GPU)。假设GPU租金成本为2美元/小时,总成本为每天87,072美元;如果所有令牌是根据DeepSeek R1的定价计算的,则每天的理论总收入为每天562,027美元,成本利润率为545%。
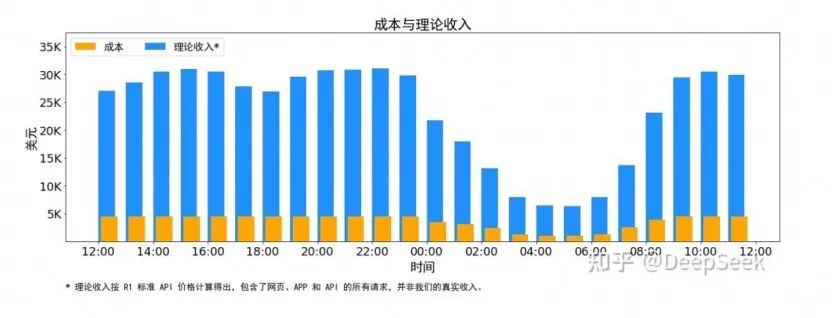
但是,DeepSeek还强调,实际收入可能不多,因为V3的定价低于R1的价格,并且晚上将有折扣。记者注意到,2月26日,DeepSeek在其API Open平台上发布了交错折扣活动的通知。根据通知,00:30-08:30的每日峰值期间北京时间是一个交错的时期,API呼叫价格已大大降低,DeepSeek-V3降至原始价格的50%,而DeepSeek-R1的50%降低至25%。 DeepSeek鼓励用户在此期间致电以享受更经济和更平滑的服务体验。
根据模型价格的细节,在标准时间段(08:30-00:30北京时间)中,V3和R1的百万个令牌输入(缓存命中)的价格分别为0.5元和1元,而百万个令牌的输出分别为8元和16元和16 Yuan和16 Yuan,R1和R1均为V3的TWICE。在折扣期(00:30-08:30北京时间)中,V3和R1的百万个令牌输入(高速缓存)均降低到0.25元,而百万个令牌产出减少到4元。
开源周结束了,更多的惊喜可能仍在途中
随着最后一个“大片”的发布,DeepSeek的开源周活动正式结束。
在过去的一周中,DeepSeek每天都开放了一个代码库,可以说这揭示了“技术家庭桶”。行业内部人士分析了这一系列的技术组件似乎是独立的,但实际上,他们共同建立了精确的协作系统,使DeepSeek能够在有限的计算能力下在最大程度上“挤压” GPU,从而在培训和推理效率方面取得了重大提高。
记者注意到,在DeepSeek邮报下来,今天发布了“最后一枚炸弹”,许多外国网民表示赞赏。例如,一个网民说,到第七天,DeepSeek也可能会发布AGI(通用人工智能,人工智能的最高目标);另一个网民说:“这是出于正确的理由做正确的事情。你绝对是一个传奇,鞠躬和致敬”。一些网民推测,DeepSeek愿意发布此信息,表明他们实际上已经达到了领先水平,其实际技术能力可能更高。
不仅如此,有些网民将DeepSeek与Openai进行了比较,并说:“成本利润率为545%,等一下,所以您的意思是我被Openai抢劫了吗?”

与DeepSeek的开源和免费的开源相比,Openai的型号一直非常昂贵。 2月28日,Openai正式发布了最新的GPT-4.5研究预览版本,该版本是一种通用大型语言模型,称为“最高情绪智力”。但是,与GPT-4O的2.5美元相比,其API通话价格高达每100万个代币输入每100万美元的代币输入,而DeepSeek的正常价格相比,GPT-4.5输入价格达到了惊人的280倍。
实际上,在GPT-4.5发行后,许多网民在评论领域抱怨价格太贵了。 OpenAI首席执行官Ultraman还承认,GPT-4.5是“大小且昂贵的型号”。 Ultraman在他的个人社交平台上说:“我们非常渴望将其启动到Plus和Pro用户,但是随着我们的成长,我们已经用尽了GPU资源。下周我们将添加成千上万的GPU,然后在加上级别上启动它。”
作为大型模型领域的“ cat鱼”,DeepSeek就像是一个刚起步,聪明和积极进取的年轻人,继续向行业中的老球员和巨人施加压力。最近,根据外国媒体的报道,DeepSeek正在加快DeepSeek-R2推论模型的发展。该模型最初计划在今年5月发布,但可能会提前计划。新模型有望生成更好的代码,并使用英语以外的其他语言进行推断。
从V3到R1,再到即将到来的R2,外界对DeepSeek充满了期望,而DeepSeek的技术突破也使世界震惊。尽管开源周暂时结束了,但更多的惊喜仍在发生。









发表评论
◎欢迎参与讨论,请在这里发表您的看法、交流您的观点。