

OpenAI升级图像生成功能后GPU过载,ChatGPT文生图应用将实施限速
随着OpenAI图像生成功能的重大升级,出现了新问题。
Openai的创始人Sam Altman表示:Chatgpt的文学和传记应用需求太高了,我们的GPU是“吸烟”(融化,最初是要融化的)。在努力提高效率的同时,我们将暂时对Chatgpt图像生成功能的功能介绍一些速率限制。
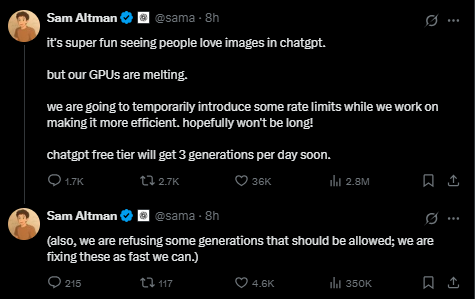
这意味着OpenAI将在ChatGpt的图像生成功能上实施临时速度限制,减少每单位时间的请求处理量,减轻GPU超负荷压力,并优先确保核心功能(例如文本生成和对话)的稳定性,这可能会暂时降低图像生成的技术优化节奏。
此前,3月26日,OpenAI在Chatgpt中启动了图像,这是一个基于GPT-4O模型的图像生成功能。用户可以通过Chatgpt和Sora平台上的自然语言指令直接生成和编辑图像,从而支持多轮迭代优化。这标志着Chatgpt已正式整合了多模式功能,例如文本,图像和代码,并实现了从单语言模型到全模式代理的飞跃。
启动此功能后,它在“移动嘴来编辑图片”的便利方面迅速流行,并且大量的“吉卜力”卡通风格的图片从个人照片和知名模因中倒入了互联网平台中。甚至阿尔特曼(Altman)也感叹了这一功能所带来的高空交通:“过去十年来我一直在努力工作,试图帮助实现超级智慧来治愈癌症和其他事物。几乎没有人关心最初的7.5年,在接下来的两年半中,在接下来的两年中,一切都会吸引每个人的厌恶。然后,有一天我醒来并接到了数百个邮件,你们却被您的男孩塞入了一个ghi,又涂上了一位ghi ni n.
山姆·奥特曼(Sam Altman)在社交平台上的新化身,由chatgpt中的图像产生

由chatgpt中的图像产生

由chatgpt中的图像产生
同时,由于图像生成功能比预期更受欢迎,因此OpenAI最初计划将功能推向所有用户,但现在被“强迫”推迟时间向自由用户打开新功能。
Dalle作为扩散模型的基本差异是GPT-4O图像生成是一种自然回归的模型,该模型本质地嵌入了Chatgpt中。 Openai根据在线图像和文本的联合分布来训练模型,以便模型可以学习图像和语言之间的关系,从而产生有用,一致和上下文感知的图像。
GPU就像一组超级快速的“画家”,可以同时处理大量计算任务。生成图片(例如Dalle和稳定扩散)需要AI来通过像素来计算像素,并且每个步骤都需要处理大量数据。让AI生成更准确,更高定义的图像依赖于GPU的大规模平行计算。 Openai提到,由于此模型创建了更详细的图像,因此图像通常需要更长的时间才能呈现,通常需要到一分钟。
通过这种方式,Wensheng图功能的用户越多,其所需的GPU计算功率就会呈指数增长。
有两个主要解决方案:更强的GPU或更有效的AI模型。前者采用“强大的砖头”路线,而后者希望优化算法,也就是说,通过改进AI算法,相同的GPU可以处理更多的任务(例如使用较小的型号或压缩技术)。
作为AI领域的领先球员,OpenAI背后的GPU储备自然是该行业的最高水平。根据技术咨询公司Omdia的分析,Microsoft是OpenAI的主要投资者,在2024年购买了约485,000名NVIDIA的Hopper Chips,是其主要竞争对手Meta的两倍,使其成为NVIDIA GPUS的最大买家。 Openai的大型模型经过Microsoft的Azure云基础架构进行培训。
可以说,由于新功能,OpenAI所面临的问题反映了AI多模式技术发展资源与需求之间的平衡问题。一方面,AI应用程序仍然对计算GPU等计算资源有巨大的需求。另一方面,该行业继续呼吁进行技术迭代,以便有效利用现有资源。










发表评论
◎欢迎参与讨论,请在这里发表您的看法、交流您的观点。