

ChatGPT图像生成功能迎来历史性升级:GPT-4o模型助力更精准文生图
在Chatgpt发布之后,图像生成功能越来越毫无用处,终于迎来了历史悠久的升级。
OpenAI首席执行官Altman在周二的一次直播活动中说,它已正式启动了基于GPT-4O模型的本地图像生成功能 - 该模型直接从文本提示中生成图像,并且不再调用独立的DALL-E文学和传记模型。

使用GPT-4O的多模式能力,ChatGpt可以更准确地遵循说明,并在图像生成时更准确地在图像上渲染文本,同时在优化图像时支持多次迭代以保持一致的角色图像。
Chatgpt于2022年底推出,只能在一开始就进行文本聊天。大约一年后,OpenAI发布了第三代图像生成模型Dall-E 3,并将其集成到Chatgpt中,但两者一直是独立的系统。最初的新鲜度过去后,AI图像发生器“理解及时单词的能力差”,尤其是“无法准确生成图片中的文本”严重阻碍了此功能在教育和工作场所等领域中的应用。
随着阿里巴巴和Google启动基于文本的图形模型,可以准确地生成今年的文本,Openai终于弥补了这一缺点。
在周二的一次演示中,Openai展示了新一代Chatgpt的图像功能已升级了多少。
首先,Chatgpt能够根据迅速单词大致准确地在图像中生成文本。在演示期间,AI根据需要成功生成一整页的语音文本,并且没有错别字。 Altman叹了口气,能够在图像生成功能中完美地呈现文本并不应该是令人惊讶的,但是我们等了这么长时间。
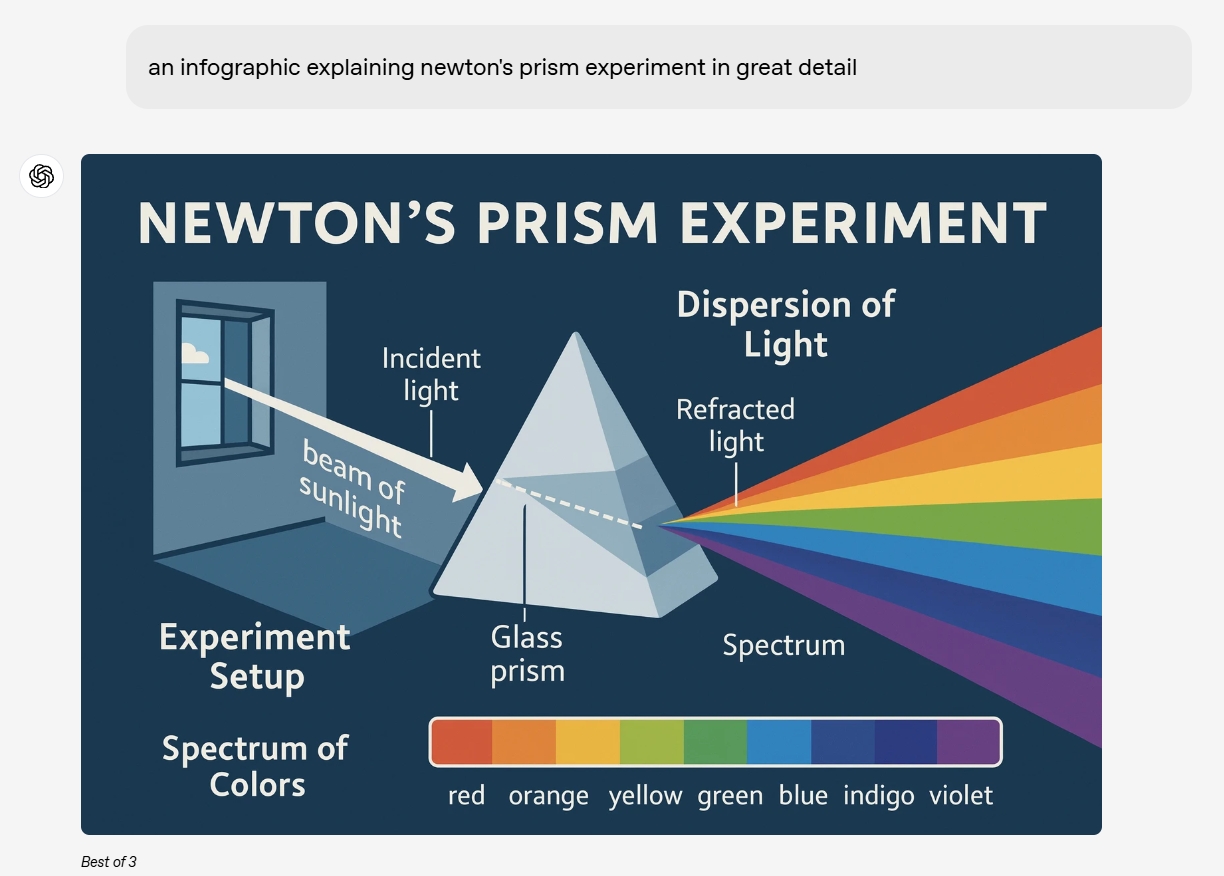
从官员给出的更多示例来看,无论是生成黑板书,还是要打印和展示科学的常识图,Chatgpt终于从在生成图像和文本的领域完全毫无用处到接近商业用途的水平。


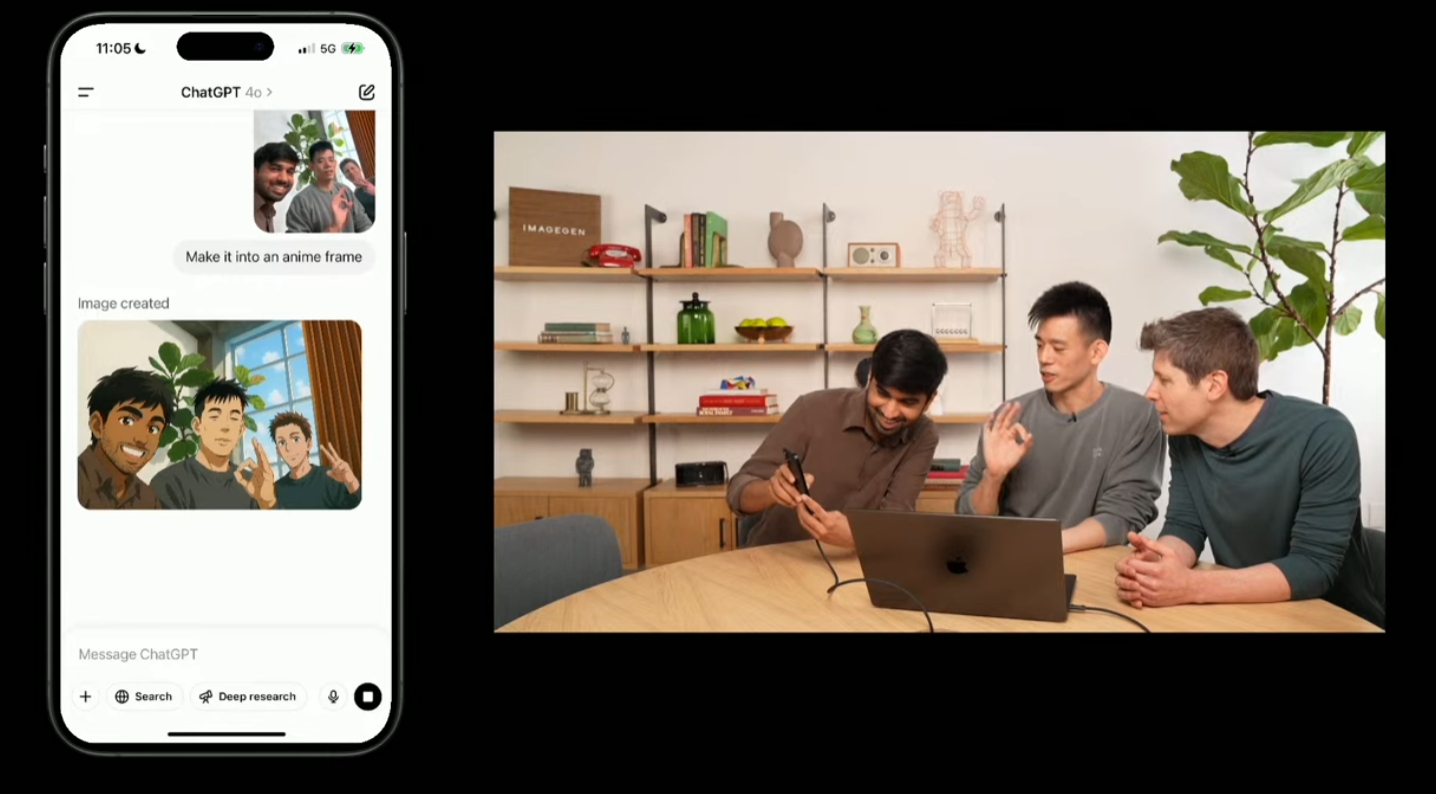
同时,Chatgpt的图像编辑功能也变得更有用。
在演示期间,两名研究人员与Altman合影,然后要求Chatgpt将照片转换为动画风格。
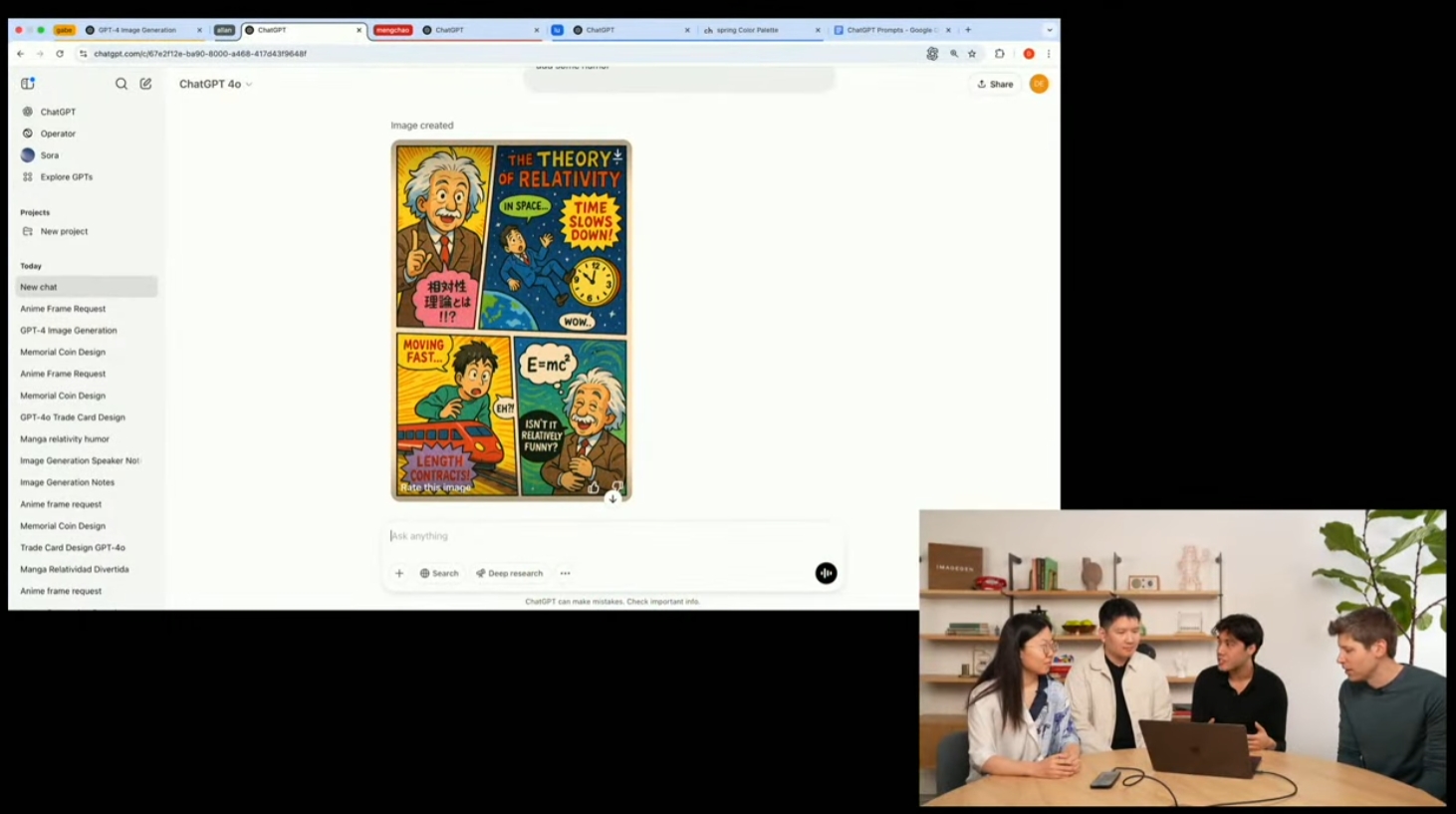
结合GPT-4O的知识基础和最终清楚地写单词的能力,Chatgpt还可以通过简单的提示单词来生成有关相对论的漫画。
说到漫画,Chatgpt现在可以根据漫画草稿一键单击生成成品。它还支持上传图片并替换漫画中的主要角色。



从商业应用程序的角度来看,该模型现在可以根据用户上传的照片和卡模板自定义新卡的组合,并根据需要显示图片和文本。


GPT4O还可以根据聊天上下文生成图像和文本,因此生成的一系列图像将是一致的,这对于设计游戏字符非常重要。

Openai承认,新的图像生成器也有一些局限性,例如受模型幻觉的影响,并且更容易发生图像生成密集文本和非拉丁蛋白字符的问题。
从周二开始,基于GPT4O的图像生成将向所有免费和付费用户推出,开发人员将能够在接下来的几周内通过API调用此功能。










发表评论
◎欢迎参与讨论,请在这里发表您的看法、交流您的观点。