

GPT-4.1震撼发布:支持100万tokens上下文,OpenAI首次推出长窗口模型
由于GPT-4.1的发布,OpenAI宣布将消除最近发布的GPT-4.5,这可以看到。
当前,如果您想体验GPT-4.1,但无法通过API身份验证,Microsoft已在Azure OpenAI上启动了该模型,并且可以使用。
GPT-4.1的亮点是什么?
GPT-4.1最大的亮点之一是它对100万个代币背景的支持,这也是Openai首次发布较长的窗口模型。
与以前的型号相比,GPT-4.1,GPT-4.1 MINI和GPT-4.1 NANO能够处理多达100万个令牌,比GPT-4O高8倍。
Openai在长上下文Evals上测试了长文本。测试结果表明,GPT-4.1系列的三个模型可以在语料库中的任何深度(无论是开始,中间还是末端,甚至在最高100万个标记的上下文中)找到目标文本,该模型都可以准确地定位目标文本。
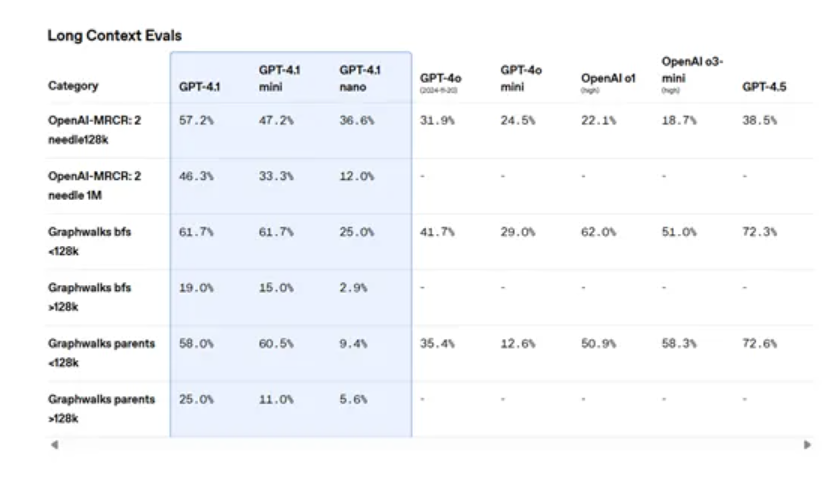
OpenAI还在多轮核心中进行了测试,以通过创建合成对话来测试该模型在长篇小说中的理解和推理功能。在这些对话中,用户和助手交替进行对话,用户可以要求模型生成有关主题的诗,然后要求生成另一首关于另一个主题的诗,然后要求生成有关第三个主题的简短故事。该模型需要在这些复杂的对话中找到特定的内容,例如“关于主题的第二个短篇小说”。
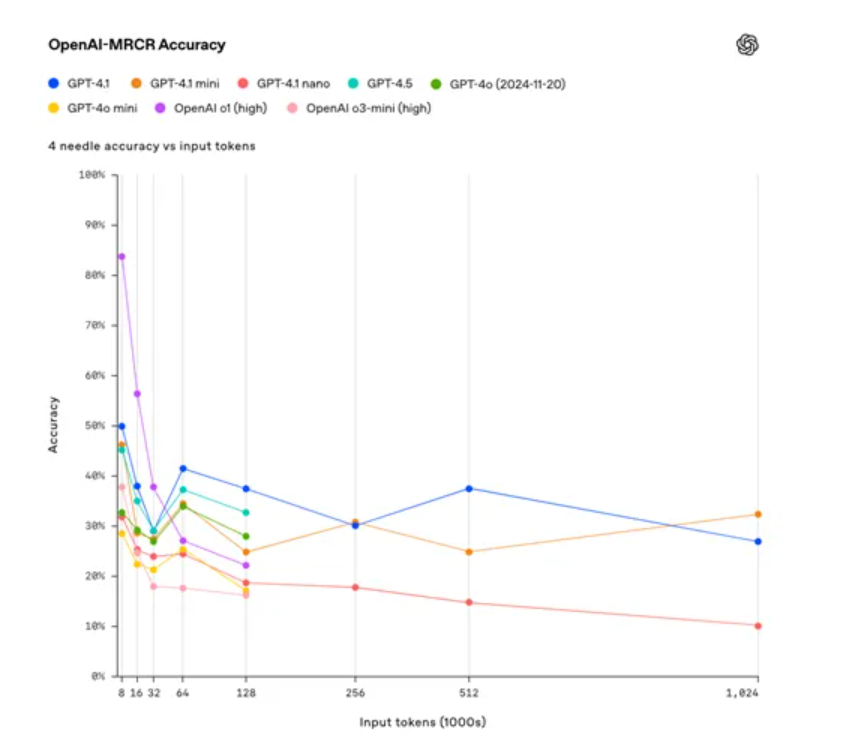
测试结果表明,在处理高达128K令牌的数据时,GPT-4.1比GPT-4O明显好,并且在多达100万个令牌的背景下仍然可以保持高性能。
在编码功能测试时,SWEBENCH评估将模型置于Python代码库环境中,从而允许其探索代码库,写代码和测试用例。结果表明,GPT-4.1的准确率达到55%,而GPT-4O仅为33%。
在多语言编码功能测试方面,Ader Polyglot基准涵盖了多种编程语言和不同格式的要求。与GPT-4O相比,GPT-4.1使差异性能翻了一番,在处理多语言编程任务,代码优化和版本管理时,其效率更高。
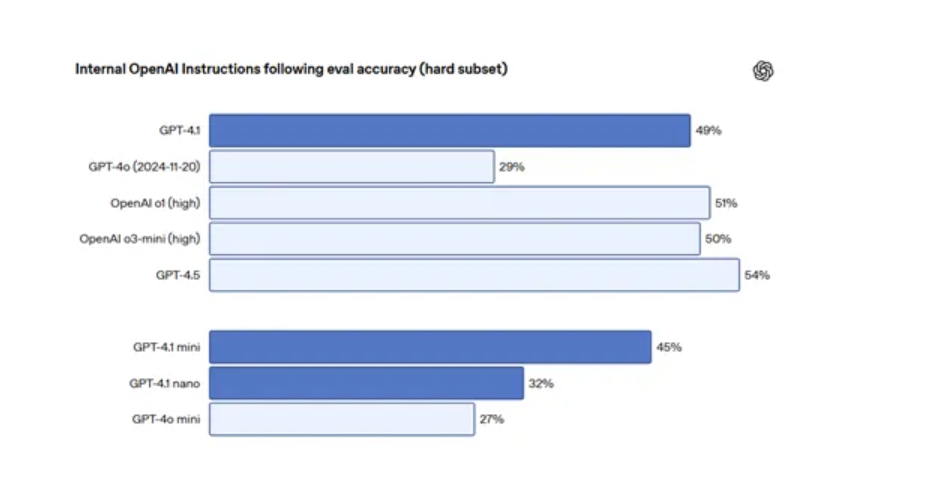
在指令合规性测试中,OpenAI构建了内部评估系统,模拟API开发人员的使用方案,并测试模型遵循复杂说明的能力。每个样本包含分类为不同类别的复杂说明,并分为难度级别。在评估困难子集中,GPT-4.1远远优于GPT-4O。
在多模式处理测试的视频MME基准测试中,GPT 4.1了解30-60分钟的未订阅视频并回答多项选择问题,达到72%的结果,达到当前最佳水平,并在理解视频内容的理解方面取得了重大突破。
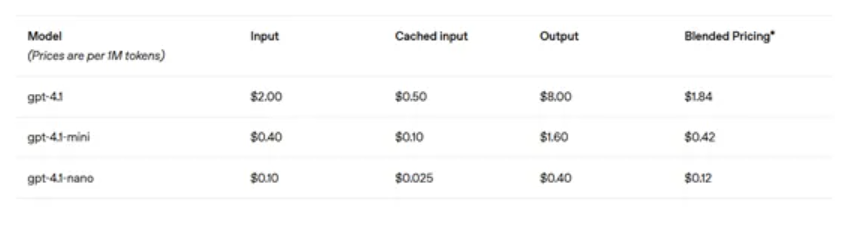
在价格方面,虽然GPT-4.1系列的性能在价格上更具竞争力。 GPT-4.1比GPT-4O低26%,而GPT-4.1 NANO(最小,最便宜,最便宜的车型)的价格仅为每百万代币12美分。
自2022年底推出热门聊天机器人以来,Openai一直在迅速升级其模型,以远远超出文本,并进入图像,语音和视频的领域。该公司正在努力保持领先于生成人工智能领域,在那里,它面临着Google,Anthropic和Musk的Xai等竞争对手的激烈竞争。
Openai写道:“我们的推理模型首次可以独立使用所有ChatGpt工具 - 网络浏览,Python,图像理解和图像生成。” “这有助于他们更有效地解决复杂的多步骤问题,并采取真正的步骤独立行动。”
该公司在上个月的一轮资金中价值3000亿美元。该公司表示,O3和O4-Mini是其第一个“使用图像思考”的AI模型。根据Openai的说法,这意味着“他们不仅可以看到图像,而且还可以将视觉信息直接集成到推理链中。”










发表评论
◎欢迎参与讨论,请在这里发表您的看法、交流您的观点。