

DeepSeek开源周首日发布FlashMLA代码库,Hopper GPU优化MLA解码内核震撼登场
2月24日,DeepSeek打开了第一个代码基flashmla。据了解,这是DeepSeek的高效MLA(多头潜在注意力)对料斗GPU进行了优化的内核,该核心专门用于处理可变长度序列,现在正在生产中。

上周四,DeepSeek宣布将在本周举行“开源周”活动,连续开设五个代码库,这引发了所有人的期望。作为“开源周”的第一枚炸弹,FlashMLA为该行业带来了许多惊喜。在本周剩下的四个工作日中,DeepSeek将继续开源四个代码库。行业内部人士分析了其他四个代码库可能与AI算法优化,模型轻巧,应用程序场景扩展等有关,涵盖了多个关键领域。
进一步突破GPU计算能力的瓶颈
根据DeepSeek的说法,FlashMLA主要取得了以下突破:
首先,BF16支持,提供更有效的数值计算功能,降低计算精度损失并优化存储带宽使用情况。
第二个是对KV(键值,一种缓存机制)缓存进行分页,采用有效的块存储策略,减少了长期推断期间的视频记忆使用情况,提高了缓存命中率,从而提高了计算效率。
第三是最终的性能优化。在H800GPU上,FlashMLA通过优化内存访问和计算路径,实现了3000GB/S内存带宽和580Tflops计算功率,从而最大程度地利用GPU资源并减少推理延迟。
可以理解的是,当传统的解码方法处理不同长度的序列时,GPU的平行计算能力将被浪费,就像卡车运输小包装一样,大部分空间空间。 FlashMLA“挤出” Hoppergpu通过动态调度和内存优化的计算能力,从而改善了同一硬件下的吞吐量。
简而言之,FlashMLA可以使大型语言模型能够在H800等GPU上更快,更有效地运行,尤其适用于高性能AI任务,进一步突破了GPU计算能力的瓶颈并降低了成本。

值得注意的是,DeepSeek能够进行大规模模型培训并显着降低成本的原因与IT提出的创新关注体系结构密切相关。 MLA(Bules的潜在注意机制),也称为低级别的注意机制,是一种与传统的多头注意机制不同的创新注意力机制。自V2模型启动以来,MLA帮助DeepSeek在一系列模型中的成本大大降低,但是计算和推理性能仍然与顶级模型相同。
计算机科学技术学院党委员会秘书吴Fei,智格大学软件学院,人工智能研究所主任,他说,我们了解一篇文章,更关心单词描绘的主题概念,而不是从头到尾的单词列表。传统大型模型中的注意力机制变得非常大,因为它需要在不同的情况下记录每个单词的邻居。 DeepSeek介绍了低级的概念,压缩了巨大的注意机制矩阵,减少了参与操作的参数数量,从而显着降低了计算和存储成本,同时保持模型的性能,从而将视频记忆使用降低到其他大型模型。 5%-13%,极大地提高了模型操作效率。
由于Flash MLA进一步破坏了GPU计算能力的瓶颈,记者注意到,一些Nvidia投资者去了DeepSeek的评论部分祈祷,希望虽然DeepSeek使GPU更有效,但它不会影响Nvidia的股价。

通过连续开源加速行业的发展过程
作为开源社区的“顶级流媒体”,DeepSeek以一种完全透明的方式与全球开发人员社区分享了最新的研究进展,从而加速了该行业的开发过程。
在开源公告中,DeepSeek还表示,它只是一家探索通用人工智能的小型公司。作为开源社区的一部分,共享的每一条代码将成为加速AI行业发展的集体驱动力。同时,DeepSeek说,没有无法实现的象牙塔,只有纯净的车库文化和社区驱动的创新。
记者注意到,在DeepSeek开源FlashMLA帖子下,许多网民称赞其开放而透明的开源精神。一些网民说:“ Openai应该向您捐赠其域名”,一些网民说:“在(开源周)的第五天,我想这将是普遍的人工智能。”
由于DeepSeek的图标是在海中探索的鲸鱼,因此网民也生动地描述了“鲸鱼正在浪潮”。
根据《证券时报》记者的说法,开源计划(开源计划)提出了专门针对AI的三个开源概念,即:
开源AI系统:包括培训数据,培训代码和模型权重。需要根据开源协议提供代码和权重,而培训数据仅需要从源头暴露(因为某些数据集确实无法公开提供)。
开源AI模型:仅需要提供模型权重和推理代码,并根据开源协议提供。 (所谓的推理代码是使大型模型运行的代码。这是一个非常复杂的系统项目,涉及GPU调用和模型体系结构)。
开源AI重量:仅需要根据开源协议提供和提供模型权重。
该行业通常认为,DeepSeek的胜利是开源的胜利,开源大型模型的创新模型为人工智能的发展开辟了新的道路。 DeepSeek以前是用模型权重开源的,并且没有更重要的组件,例如开放式培训代码,推理代码,评估代码,数据集等,因此它属于第三种开源。
一位高级行业内部人士告诉记者,DeepSeek启动R1并发布了一份技术报告后,许多团队试图重现R1模型,但是由于涉及许多重要且重要的技术细节,因此有必要实现真正的再现。这很困难,需要很长时间。但是,该行业的开源基本上是开源模型的重量,与其他开源模型相比,DeepSeek的开源已经是最高的,最彻底的。
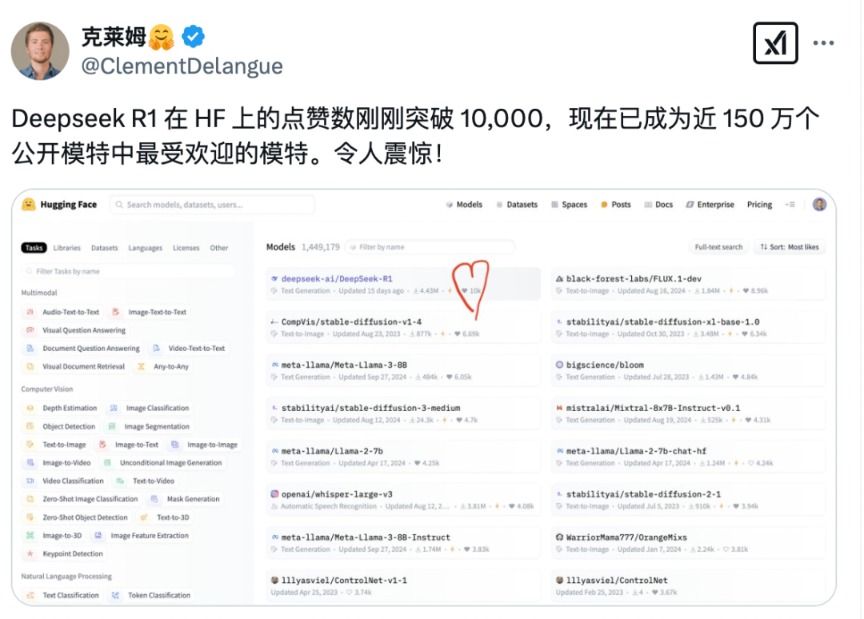
因此,该行业也称为“源神”。同样,如今,DeepSeek-R1在著名的国际开源社区拥抱面孔上获得了10,000多个喜欢,成为该平台近150万个模型中最受欢迎的大型型号。 Hugging Face Ceo Clement Delangue还尽快在社交平台上分享了好消息。
Minsheng Securities Research Reports认为,所有DeepSeek模型都是开源模型,也就是说,所有应用程序制造商都有大型模型可以匹配顶级AI,并且还可以手动开发和部署它们,这将加速AI应用程序的开发。模型的成本越低,开源模型的开发越好,模型部署和使用的频率就越高,并且使用情况越大。
研究报告进一步指出,经济学中著名的“杰文斯悖论”提出,当技术进步提高资源使用效率时,它不仅不会减少这种资源的消费,而且还会刺激更大的需求,因为降低了需求使用。 ,最终导致总资源使用的增加。因此,从更长的周期开始,DeepSeek的开发将加速AI的普及和创新,从而提高计算能力需求,尤其是对推理计算能力的需求。









发表评论
◎欢迎参与讨论,请在这里发表您的看法、交流您的观点。