

AI不眠,DeepSeek R1引发美股科技股抛售潮,芯片巨头等多股暴跌
AI从不睡觉。
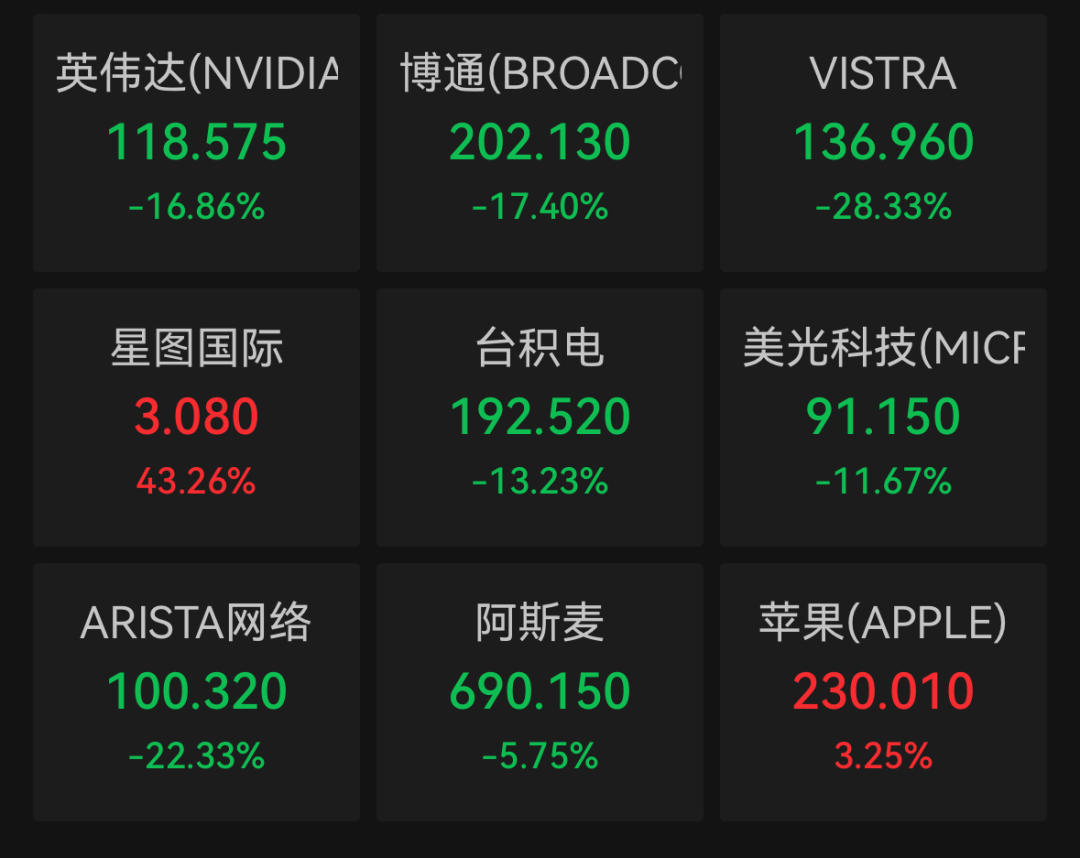
由于DeepSeek的R1大语言模型,华尔街引起了华尔街对美国公司模型成本和人工智能库存泡沫的恐慌的质疑,美国股票引发了一波科学和技术库存。芯片巨头的股价当天下降了约16.86%,单天的市场价值蒸发了约6000亿美元,Broadcom下跌了17.4%,Chaowei半导体公司下跌6.37%,Meiguang Technology下跌了11.67%,TSMC下跌了13.23%。 ,微软下跌了2.14%。此外,在人工智能领域(例如电力供应商)的衍生产品也受到严重损害。美国联邦的股价下跌了20.85%,维斯特拉的股价下跌了28.33%。
白宫人工智能和加密货币负责人戴维·萨克斯(David Sacks)在X上张贴,他说,DeepSeek R1的表现表明,人工智能的竞争将非常激烈,也证明了美国总统特朗普废除拜登的行政命令是正确的举动。萨克斯说,拜登通过行政命令在美国写了一家人工智能公司。他还说:“我对美国有信心,但我们不能自满。”
在使用R1型号冲击硅谷和Crit Wall Street之后,DeepSeek在深夜扩大了技巧。 Liang Wenfeng在1月27日下午10点左右在社交平台上表示,在社交平台上说,新版本的DeepSeek即将发布。三个多小时后,人工智能开源社区Huggingface显示,DeepSeek发布了一系列名为Janus-Pro的开源多模式模型,Janus-Pro和Janusflow从10亿到70亿。
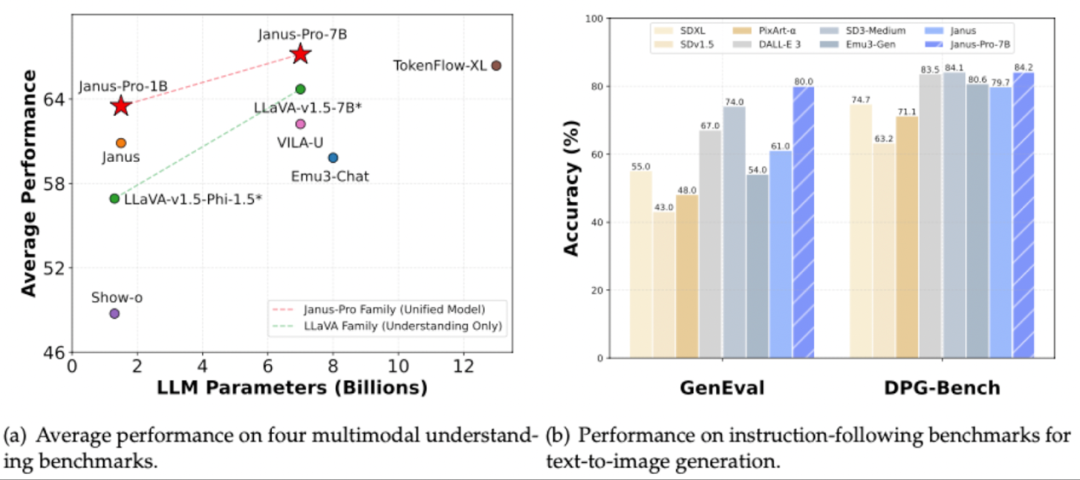
这次发布的新模型着重于Wensheng的能力。其中,在Geneval和DPG基础参考测试中,Janus-Pro-7b的70亿参数以及80%和84.2%的准确性测试结果击败了Top Image生成模型,例如DALL-E3和Stablebablefusion模型。据了解,该项目使用MIT许可证开源,开发人员可以通过开源社区GitHub获得完整的代码。 DeepSeek团队还说,Janus-Pro的简单设计和出色的性能使其预计将成为下一代统一的多模式模型的重要选择。
根据DeepSeek发布的一份报告,Janus-Pro Advanced Model是Janus先前发布的改进版本。与Janus相比,Janus-Pro包含优化的培训策略,扩展培训数据,并扩展到更大的模型量表。通过这些改进,Janus-Pro在多模式的理解和文本对象指令方面取得了重大改进,同时提高了文本对图像生成的稳定性。
具体而言,作为一种新颖的自我回归框架,Janus-Pro统一地理解并生成多模式状态,将视觉编码解耦,以实现多模式的理解和产生。它通过将视觉编码作为单独的路径解耦来解决以前方法的局限性,与此同时,它仍然使用单个和统一的转换器体系结构进行处理。
值得注意的是,DeepSeek透露,对于1.5b/7b的两个参数,整个训练过程是在16/32节点的群集上执行的。每个节点配备8个NVIDIAA100(40GB)GPU,1.5B/7B型号的训练时间约为7/14天。换句话说,DeepSeek在256 NVIDIA A100工作了两个星期,并训练了击败Openai的Dall-E3和Stablediffusion的模型。
DeepSeek在报告中还显示了具体的结果。例如,使用“秋天躺在木制门廊上的狗的黄金恢复”和“一个有雀斑的年轻女子戴着草帽,站在金麦田里”,Janus -Pro -7b可以准确捕获提示中的语义信息,并生成逻辑和连贯的图片。但是,尽管它包含大量图像细节,但Janus-Pro-7b当前仅支持分辨率为384×384的图像。

此外,Janus-Pro-7b还具有图像识别函数。根据展示案例,在为Janus-Pro-7b提供图片并询问“猜测在哪里”时,Janus-Pro-7b可以根据图片的特征猜测。著名的桑坦尤尤岛(Santan Yueyue Island)并进一步分析了:“图片中的建筑物是桑坦·亚尼(Santan Yinyue)的凉亭,周围环境是平静的湖泊,远处有滚动的山脉。自然景观和丰富的历史文化。”
实际上,DeepSeek一直在多模板中探索。去年,DeepSeek启动了基于自我回归的统一模型的多模式理解,并生成了统一的模型,以使视觉编码分发以实现多模式的理解和生成。进入2025年,该公司进一步将Janus升级为Janus-Pro。在被问及公司在实现通用人工智能过程中的坐标之前,李安格·温芬(Liang Wenfeng是自然。语言本身。
目前,DeepSeek的C端应用主要集中在文本功能上,并且不可能生成图片或识别图像。记者给了DeepSeek一张新年的照片,但DeepSeek只给出了图片创作的颜色和原色,并说它无法直接生成图片。 。










发表评论
◎欢迎参与讨论,请在这里发表您的看法、交流您的观点。