

DeepSeek-R1模型超越OpenAI o1,通用人工智能AGI研发商DeepSeek登顶苹果应用商店下载榜
27日,DeepSeek应用登顶苹果中国和美国应用商店免费APP下载榜,超过美国下载榜上的ChatGPT。


据悉,DeepSeek于2025年1月发布了性能对比OPENAI O1的DEEPSEEK-R1模型正式版。该模型在后训练阶段采用了大规模增强学习技术。在只有很少标签数据的情况下,大大提高了模型的推理能力。
该模型发布后,引起广泛热议。 CNBC 称:“一个鲜为人知的中国人工智能实验室发布了一个人工智能模型,虽然其建设成本较低,但性能超越了美国最好的人工智能模型,从而引发了整个硅谷的恐慌” ”

1月26日,有消息称DeepSeek闪崩,服务器繁忙。当日16时,上证报记者透露,DEEPSEEK型号可以正常使用。
公开信息显示,DeepSeek旗下企业深入杭州寻求人工智能基础技术研究有限公司,该公司由梁文峰间接控股83.2945%。据悉,梁文峰出生于广东,毕业于浙江大学。此前曾从事量化投资工作。

低成本、高性能
DeepSeek-R1模型最显着的特点是性能强、成本低。
公开资料显示,DeepSeek-R1的性能可对标OpenAI O1正式版,但deepseek-R1 API服务定价为每百万产出token1元(缓存)/4元(缓存),token16每百万产出产出代币16元 每百万产出产出代币16元 精华 有业内人士告诉记者,这个收费标准大约是Openai O1运营成本的一-30分之一。
DeepSeek-AI团队的论文表明,DeepSeek R1的关键点在于其创新的训练方法——DEEPSEEK-R1-Zero路线。 (RL)用于基本模型,不依赖监督和微调(SFT)和标记数据。
事实上,低成本和高性能一直是DeepSeek模型的“卖点”。
DeepSeek于2024年12月推出Deepseek-V3模型,其多项评估结果超越了Qwen2.5-72B和LLAMA-3.1-405B等其他开源模型,以及全球顶级闭源模型GPT-4O的GPT-4O性能和型号均处于世界领先水平。而Claude-3.5-SONNET不管博中。
值得注意的是,该模型开发仅两个月,投入不到 600 万美元,并且模型训练使用性能有限的 Nvida H800 显卡。相比之下,Meta的LLAMA-3.1-405B训练成本高达6000万美元,使用的计算资源是DeepSeek-V3的11倍。
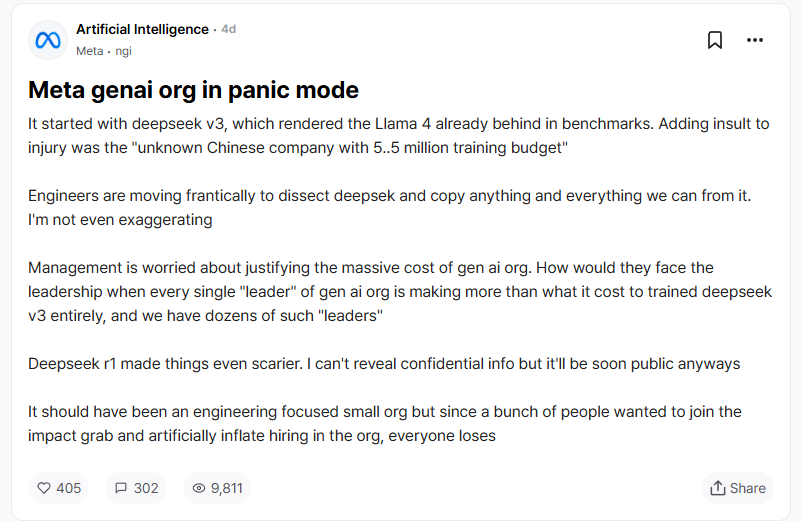
在美国匿名职场社区 Temblind 中,Meta 员工曾表示 DeepSeek 的低成本和高效率可以让团队面临预算理性:“生成 AI 开发团队中每个领导者的薪资比整个团队的成本得到更多补偿” DeepSeek-V3 甚至更高,我们有几十个这样的领导者。”
市场反应激烈
DeepSeek-R1模型的发布引起了激烈的讨论。业内人士表示,之所以市场反应如此剧烈,Deepseek的例子说明AI技术并没有明显的“护城河”,模型技术过剩已经成为常态。
微软首席执行官萨蒂亚·纳德拉 (Satya Nadella) 在达沃斯世界经济论坛上表示:“DeepSeek 的新模型令人印象深刻。他们不仅有效地开发了一个开源计算合理时的模型,而且计算效率极高。”
经济学家指出,美国目前训练一个大型语言模型需要花费数千万美元,而DeepSeek花费不到600万美元。这种廉价的培训正在随着模型设计的发展改变整个行业,这可能会带来更专业的特定用途模型,打破赢家的市场格局。
此外,AMD宣布DeepSeek-V3模型已集成在Instinct MI300X GPU上,并在SGLANG的帮助下优化了性能。 AMD还表示,此次整合将有助于加速尖端人工智能应用的开发。

DeepSeek的高人气也引起了国内资本市场的关注。相关业内人士表示,人工智能有望在春节前后继续成为资本市场追逐的热点板块。









发表评论
◎欢迎参与讨论,请在这里发表您的看法、交流您的观点。