

中国联通利用DeepSeek-R1满血版模型实现难度自适应微调与二次蒸馏优化
难度适应性微调:为了实现难度适应模型推断,中国Unicom使用DeepSeek-R1全血版本模型来生成数据,通过复杂量化模块构建长度偏好数据,然后从中选择一个较短的长度抽样的答案以获取简单的问题。难题的答案,以更长的长度选择答案,以使答案长度与当前问题的复杂性相匹配。在此基础上,DeepSeek-R1经过微调,因此微调模型具有适应不同难度级别问题的缓慢思考。
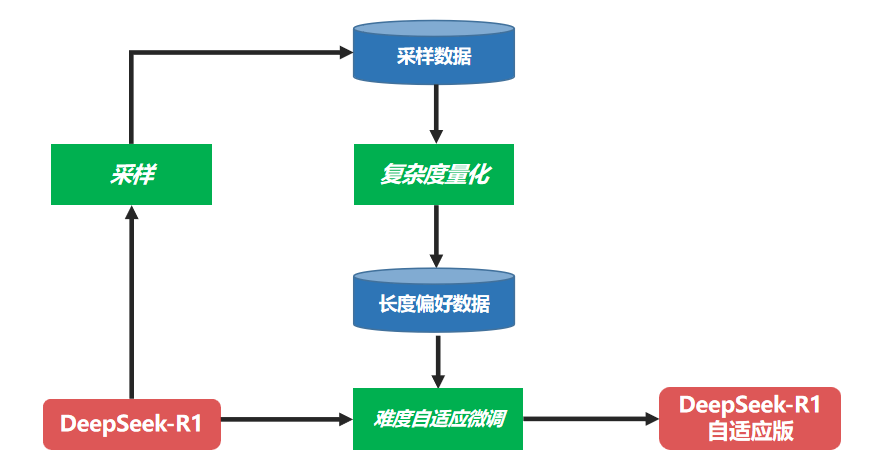
特定的转换过程如下图所示。自适应慢速思考DeepSeek-R1全血版本模型训练流程图
次要蒸馏:DeepSeek-R1的一系列蒸馏模型,因为所使用的蒸馏数据来自训练R1全血版本时使用的训练数据,而不是由R1的绩效全血的更好的全血版本生成的数据本身,这将导致由此产生的蒸馏模型无法充分学习R1全血版本的能力,并且蒸馏效应大大降低了。为了解决这个问题,中国Unicom使用了二级蒸馏策略,也就是说,使用DeepSeek-R1全血型版本将累积的高质量数据转换为长脑链格式数据,包括深思维过程。在DeepSeek-R1蒸馏系列模型中,进行另一种微调以使模型具有更强的推理能力。
难度适应性增强学习:在模型的继发蒸馏之后,中国Unicom从DeepSeek-R1的构建思想中进一步学习,并提出了基于GRPO算法的难度适应性增强算法DA-GRPO(难度适应性GRPO)。次级蒸馏模型受到困难的自适应增强学习训练,以进一步改善其推理效果。除了使用传统的基于规则的正确性奖励,格式奖励和语言一致性奖励外,Da-Grpo还根据每个问题的复杂性和生成的答案的长度来校准奖励。具体而言,如果模型对一个简单问题的回答更长,则奖励分数将受到相应的惩罚。同时,如果该模型输出更长的答案,则将给出更高的奖励分数,以鼓励其更充分地思考。这样,通过提高样本答案的奖励分数之间的区别,该模型可以根据问题的难度输出相应的长度答案,从而大大降低了答案的冗余和资源消耗,同时确保了答案的准确性推理,从而实现了使用不同难度水平的问题的能力。自适应缓慢思考。
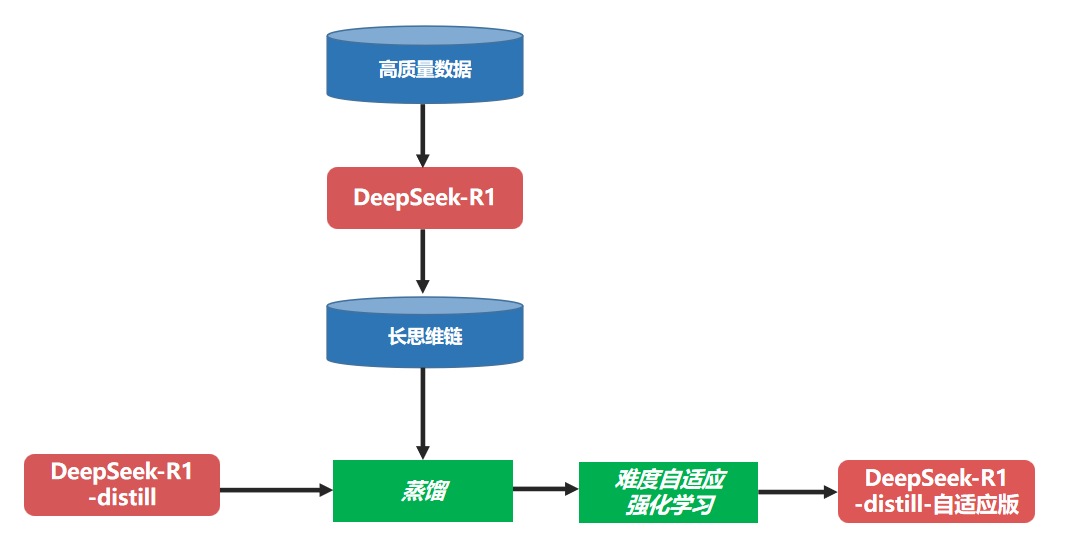
自适应慢速思考DeepSeek-R1蒸馏版型号训练流程图
节省大约30%的推理计算
中国Unicom使用DeepSeek-R1-Distill-32b模型验证了上述方法的效果。通过比较数学任务评估集(MATH500)和特定实验的比较和特定实验,可以看出,在不同难度水平的问题上,自适应难度在不同难度水平上产生的答案长度显着低于原件,并且对于最高的难度(5级),输出答案长度下降了最大,这反映了该模型有能力适应不同难度水平的慢速思考。经过评估,这种创新的自适应慢思维方法可以平均节省约30%的推理计算,从而大大减少冗余输出,并有效地改善用户体验。
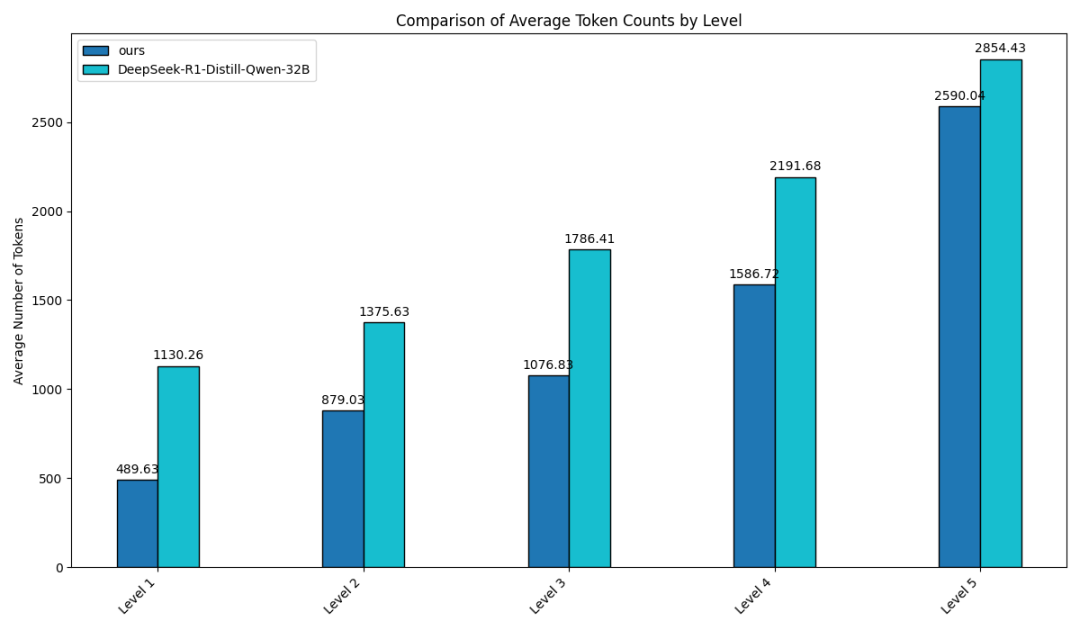
答案长度比较:原始DeepSeek-R1-Distill-32B(浅蓝色)与自适应版本(深蓝色)









发表评论
◎欢迎参与讨论,请在这里发表您的看法、交流您的观点。