

DeepSeek-R1模型引发全球关注:中国AI创业公司DeepSeek在海外掀起巨浪
自1月20日Deepseek发布新模型Deepseek-R1并同步开源模型权重以来,这家来自中国的AI创业公司引起了全球AI科技圈的关注。同时,包括《纽约时报》、《经济学人》、《华尔街日报》等在内的多家英美主流媒体纷纷报道了DeepSeek的研究进展,并高度赞扬了其模型的强大性能。其中,CNBC发文称:“DeepSeek-R1因其性能超越了其在美国的顶级同类型号,而且成本更低、算力消耗更少,引起了硅谷的恐慌。”
值得注意的是,Nvidia的竞争对手、知名半导体公司超微半导体(AMD)昨天发布消息称,DeepSeek-V3模型已经集成到AMD的芯片产品InstinCT MI300X GPU中。该模型是用SGLANG实现最多的。良好的表现。 DeepSeek-V3优化了AL推理。业内人士表示,AMD作为全球领先的芯片厂商,通过与Deepseek的合作,将为AI推理带来新的想象,也有望撼动“Nvidia+Openai”主导的行业格局,改变现有的游戏规则。
去年年底DeepSeek-V3发布后,业界掀起了DeepSeek“怪圈”“怪圈”的讨论。 DEEPSEEK-R1这两天引起海外广泛讨论后,1月24日英伟达股价下跌3.12%。
值得一提的是,1月26日,有网友反映DeepSeek崩溃,服务器繁忙。 14时56分,证券时报记者发现可以正常使用。
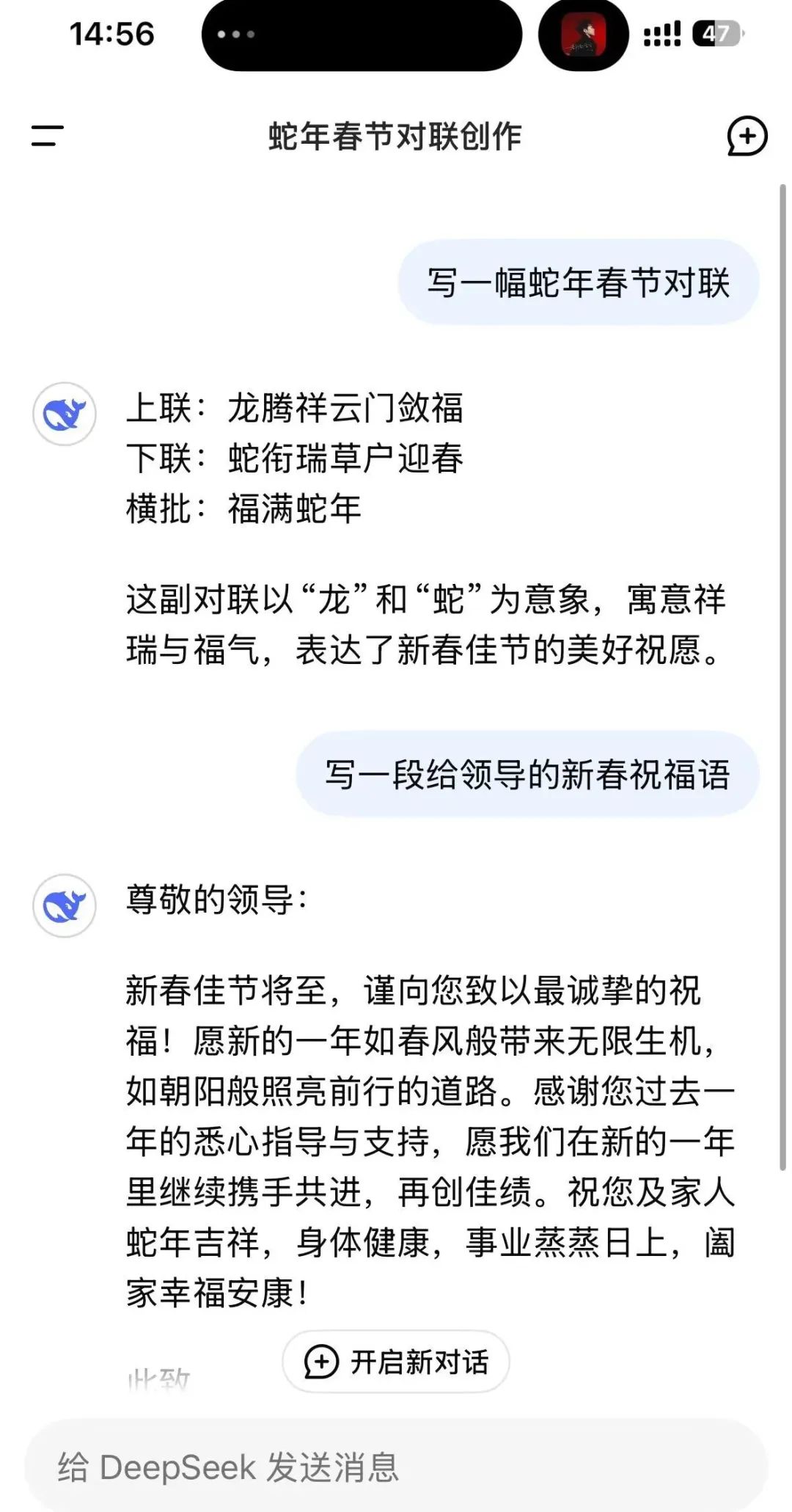
据媒体消息,Deepseek回应称,今天下午(1月26日)Deepseek确实出现了本地服务波动,但问题在几分钟内就得到了解决。该事件可能与新机型发布后访问量激增有关,官方状态页面并未将其标记为事故。

Deepseek让硅谷巨头冷静
据Deepseek介绍,其最新模型Deepseek-R1在后训练阶段采用了大规模增强学习技术,在很少有标签数据的情况下,大大提高了模型推理能力。在数学、代码、自然语言推理等任务上,表现都是官方版本的Openai O1。
该模型发布后,引起了海外AI圈众多科技领袖的讨论。例如,英伟达高级研究科学家 Jim Fan 在个人社交平台公开发布推文:“我们正处于这样一个历史时刻:一家非美国公司正在延续 OpenAI 的最初使命——人类。
近日在2025年达沃斯论坛上,AI初创公司SCALE AI创始人Alexandr Wang公开评价Deepseek的新模型,表示“新的Deepseek模型的表现令人印象深刻,尤其是在模型方面”我们必须要讲道理。我们必须要讲道理。”他还直言不讳地说。 DeepSeek的AI模型性能与美国最好的模型大致相当。另一家知名AI创业公司、被称为Google Killer的CEO Aravind Srinivas甚至直接评价:“Deepseek配备了OpenAI。”
DeepSeek这匹AI黑马在去年底发布Deepseek-V3时就引起了硅谷的关注,并因其低调的风格被称为“来自东方的神秘力量”。新车型发布后,这家硅谷巨头既兴奋又紧张。匿名社区 TeamBlind 中的一条 Meta 员工消息称:“Meta 的生成人工智能团队陷入了恐慌。”该帖子进一步爆料称,Meta 工程师目前正在拆解 DeepSeek,试图复制其中的所有内容。 “我没夸张,事情这么紧急。”
同时,由于DeepSeek擅长“小成本办大事”,因此通过采用创新的架构和优化算法,具有更高的经济训练效果和更高效的推理能力。 DeepSeek-V3的总训练成本仅为550万美元左右,不到LLAMA-3405B超过6000万美元的十分之一。爆料还称,META管理层正面临严峻的财务压力。 AI部门的AI高管数十名。 “每个人的年薪超过了Deepseek-V3的所有培训费用。投入产出比成了他们的噩梦。”
不仅硅谷巨头们震惊,英国和美国的众多主流媒体也都对Deepseek进行了关注。例如,英国媒体经济学家指出,“目前训练一个大型美语模型要花费数千万美元,而Deepseek花费不到600万美元。这种廉价的训练正在随着模型设计的发展改变整个行业。”它可能会带来针对特定用途的更专业的模型,并打破赢家的市场结构。”

英国《金融时报》也发表了题为《中国一家小型AI初创公司震撼硅谷》的文章。文章称,“R1模型的发布在硅谷引发了激烈的争论,主题包括在Meta和Anthropic方面拥有强大资源的美国人工智能公司能否保持技术优势。”采取重大措施将其商业化。
股东们也着急:DeepSeek锋锐Nvidia?
在MERA员工的匿名社区TeamBling上,证券时报记者发现,不少帖子都讨论了Deepseek。除了模型成本和性能等技术讨论之外,一些股东还发起了题为“Nvidia是否应该担心DeepSeek”的投票。帖子还给出了一些“以前的情况”,提醒 DeepSeek 以不到 600 万美元的价格在性能较差的 GPU 上训练 V3 模型。 O1型号与Openai相当。
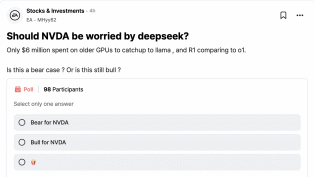
事实上,自从DeepSeek去年底发布V3模型以来,业界就开始关注DeepSeek的成功。 DeepSeek背后更大的意义在于,通过软件优化,在有限的硬件资源下实现顶尖的模型性能,减少对高端GPU的依赖本质上有观点认为,DeepSeek极低的训练成本—— V3预示着大规模模型对算力的需求将大幅下降,而这无疑将是全球AI算力的核心供应商英伟达。
据证券时报记者了解,大模型主要分为训练和推理两个阶段。训练是指利用大量数据训练大型模型,通常需要较高的计算能力和存储资源。任务(如询问并生成文本、识别图片和视频等)。这两者使用不同的芯片。近两年,各大厂商加大了模型培训力度。计算能力主要体现在训练阶段。模型训练是Nvida GPU的优势。但随着基础训练模型的爆发和AI应用的爆发,算力的增长可能会更多集中在推理方面。
同时,Deepseek不仅大大降低了模型训练的成本,而且此次发布的新模型R1还同步了开源模型的权重。完整的训练细节遭到公开质疑,挑战了闭源系统的优势。由于DeepSeek降低了AI模型技术和使用门槛,有市场人士担心DeepseekR1的崛起可能削弱市场对英伟达AI芯片的预期,并对Nivine达达的市场地位和战略布局产生影响。
不过,也有观点认为,DeepSeek只计算预训练的算力消耗,但数据配比、合成数据的生成和清洗也需要消耗大量算力。同时,训练成本的降低或许并不意味着对算力的需求减少。只有模型厂商才能用更划算的方式去做模型极限能力的探索。中信证券研报也指出,DeepSeek-V3意味着AI大型模型的应用将逐步走向普惠,助力AI应用广泛落地。同时,训练效率的显着提升也将有助于推理算力的需求。









发表评论
◎欢迎参与讨论,请在这里发表您的看法、交流您的观点。