

2月4日盲测榜Qwen2.5 - Max成绩佳 中国大模型新荣耀
![K图 09988_0]](http://news.lianzhou.cn/zb_users/upload/2025/05/1738706788110_0.png)
在2月4日清晨,三方基准测试平台Chatbot Arena宣布了最新的大型盲型测试清单。 Qwen2.5-Max刚刚发布的Qwen2.5-Max超过了DeepSeek V3,O1-Mini,Claude-3.5-Sonnet和其他型号。 1332分在世界上排名第七,这也是中国型冠军。同时,QWEN2.5-MAX在数学和编程等单项功能中排名第一,在硬提示中排名第二。
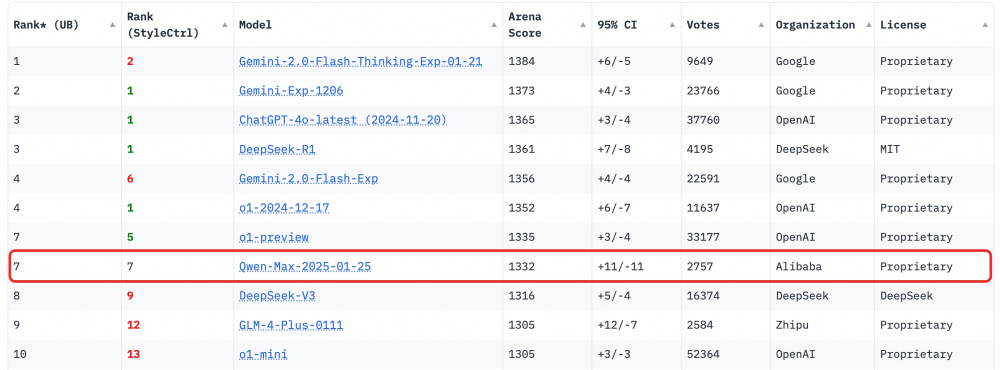
据了解,Chatbot Arena是由LMSYS ORG启动的大型模型性能测试平台,目前集成了190多个型号。该列表使用匿名方式将用户向用户提供给用户进行盲目测试。用户根据真实的对话经验投票支持模型功能。因此,聊天机器人体育馆LLM排行榜已成为该行业认可的最公平和权威的清单之一,它也是世界顶级模型中的重要舞台。

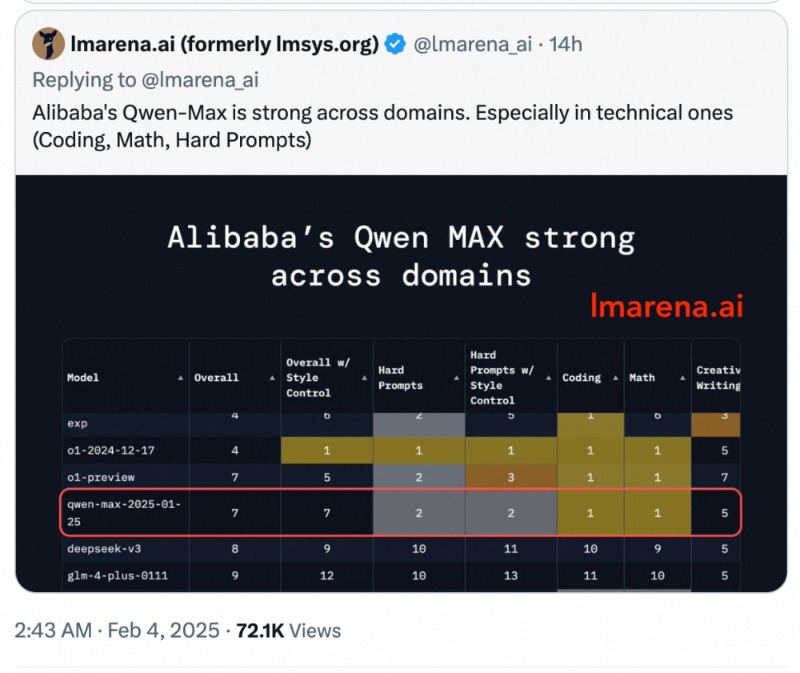
聊天机器人竞技场正式评论:阿里巴巴的QWEN2.5-MAX在许多领域,尤其是专业和技术方向(编程,数学,硬提醒等)的表现强劲。
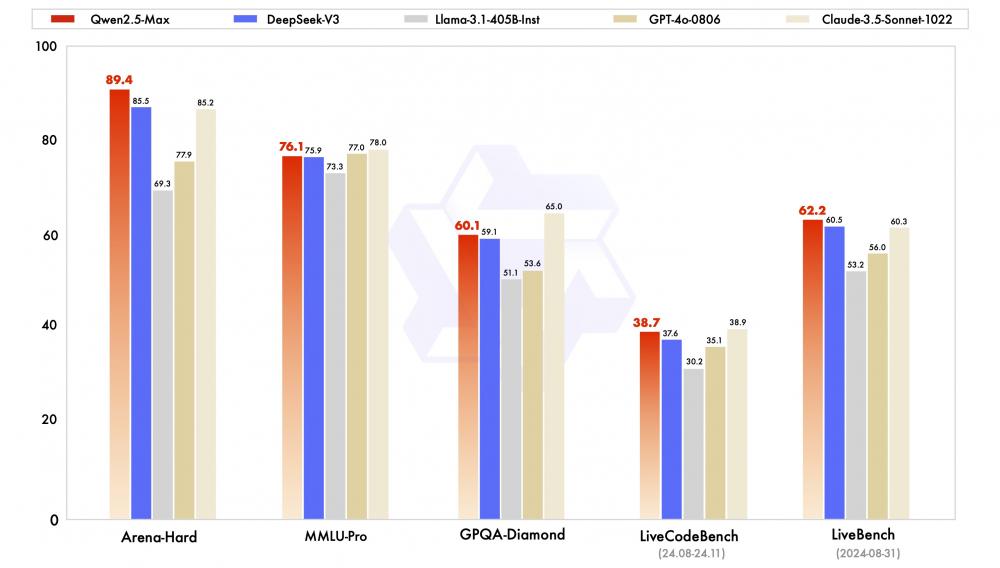
Qwen2.5-Max是一周前由阿里巴巴云人员发布的最新MOE模型,表现出色。在主流基准测试中,例如Arena-Hard,LiveBench,LiveCodeBench,GPQA-Diamond和Mmlu-Pro,将Qwen2.5-Max与Claude-3.5-Sonnet进行比较,并且几乎超过GPT-4O,DeepSeek-v3和Llama -3。 1 -405b。
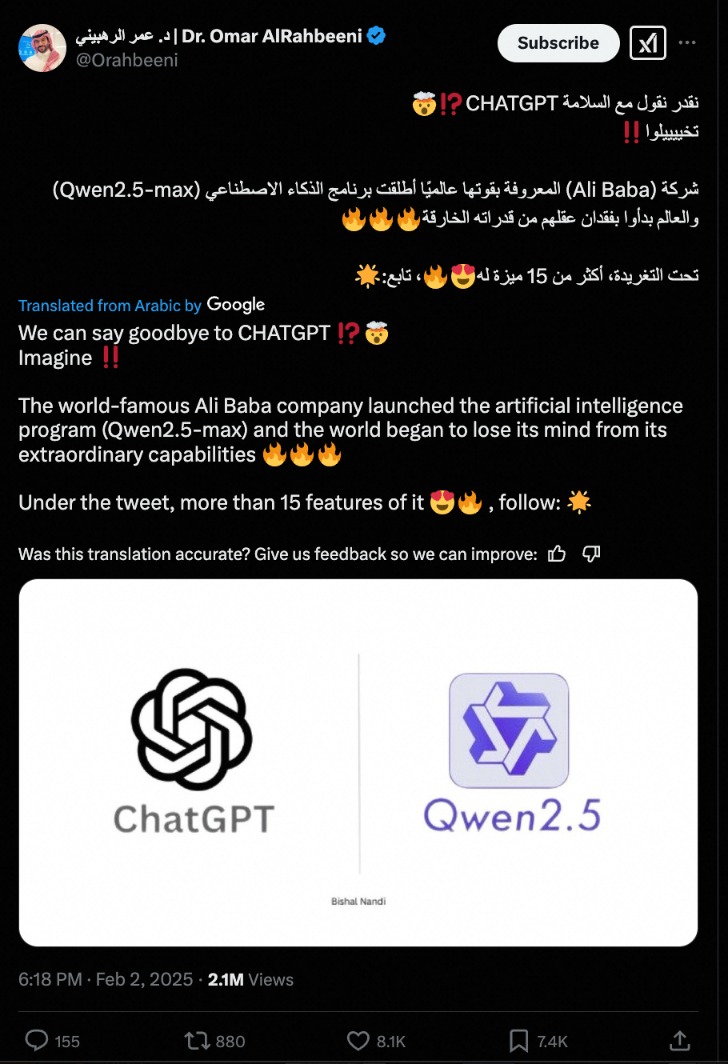
Qwen2.5-Max发行后,他立即在国内外的大型模型社区中引起了激烈的讨论:聊天机器人竞技场正式发推文说,由Qwen2.5-Max代表的中国模型正在追赶;一些从业者在与表演的同时感到惊讶,他还兴奋地说:“我们可以告别chatgpt!”
目前,公司可以在阿里巴巴Cloud Bai Lian中调用QWEN2.5-MAX模型的API服务,开发人员还可以在QWEN聊天平台上免费体验最新的模型。









发表评论
◎欢迎参与讨论,请在这里发表您的看法、交流您的观点。