

腾讯混元视频生成大模型正式上线,开源130亿参数,支持中英文双语输入
12月3日,备受业界关注的腾讯混元视频生成模式正式上线。
此前,腾讯混元模型已陆续推出文生文、文生图、3D生成等能力。此次推出的视频生成能力,被认为是混元系列大机型最后一块重要拼图。
与此同时,腾讯宣布将开源大视频生成模型,该模型拥有130亿个参数,是目前最大的开源视频模型。
目前,通过腾讯元宝App,依次点击“AI申请”和“AI视频”即可使用该功能,但需要前期申请。

优异的评价表现
记者体验发现,与大多数大视频生成模型一样,腾讯混元视频生成大模型的用户只需输入描述即可生成视频。目前视频生成功能支持中英文双语输入、多种视频尺寸、多种视频清晰度。
去年以来,国内外各类大型车型百花齐放。尤其是以Sora为代表的国外大型视频一代模式,给了电影、电视、游戏等行业一个“颠覆”的机会。
今年以来,字节跳动、商汤科技、达摩院也相继推出了大视频生成模型。作为国内数字科技领军企业之一,腾讯的混元视频模式备受市场关注,“什么时候推出、效果如何?”等。
腾讯将本次推出的大规模混元视频生成模型与国内外众多顶级模型进行了评估和对比。结果表明,混元视频生成模型在文本视频一致性、运动质量、画面质量等多个维度均领先。在人物、人造场所等场景中表现尤其出色。
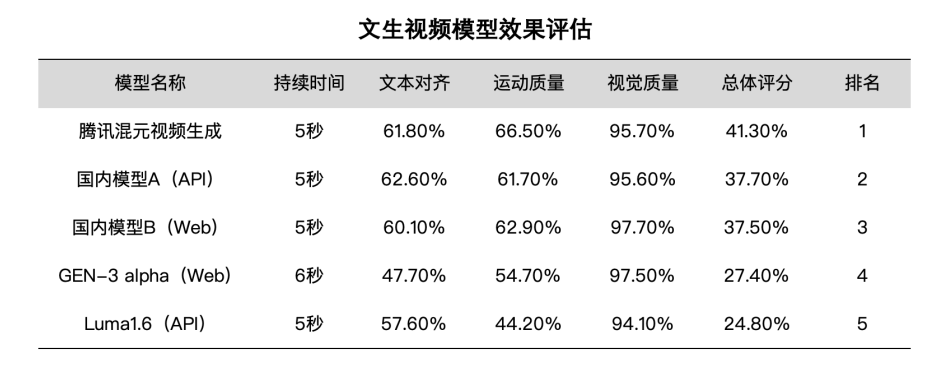
评测结果显示,腾讯混元视频生成大模型可以实现超真实的图像质量,生成与提示词高度一致的视频图像,且图像平滑不易变形。
腾讯同时发布了多个测试生成视频。可以看到,在生成冲浪、跳舞等大型运动场景时,腾讯混元可以生成流畅合理的运动镜头,物体不易变形;光影反射基本符合物理定律。在镜子或镜子场景中,镜子内外的运动可以是一致的。
同时,该机型还可以在主角不变的情况下自动切镜头,这是业内大多数机型所不具备的能力。
“拥堵”赛道再添有力竞争者
今年2月,OpenAI发布了首款视频生成模型Sora,吹响了视频生成大模型赛道冲锋的号角。
仅看中国,今年4月,圣数科技与清华大学联合发布了长时长、高一致性、高动态的视频生成模型Vidu; 6月,快手发布大视频生成模型科灵AI; 7 9月,商汤科技推出最新AI视频模型Vimi,阿里巴巴达摩院发布AI视频创作平台迅光; 9月,字节跳动推出两款AI视频生成模型PixelDance和Seaweed。
根据以往的经验,腾讯几乎不是第一批在大机型细分赛道“突围”的公司,但在相关产品正式发布后,产品表现已经较为出色。
生成高质量视频的时长是判断大型视频生成模型的关键指标之一。腾讯混元此次发布的大视频生成模型可以生成长达16秒的视频,与美国公司Meta推出的大视频生成模型相当。
腾讯混源相关负责人表示,混源领先的大规模视频模型生成能力主要得益于其技术创新。它采用了与Sora类似的DiT架构,并在架构设计上做了很多升级。
此外,混合视频生成模型适用于新一代文本编码器,以提高语义合规性。语义跟随能力强,能够更好应对多主体的描绘,实现更详细的指示和画面呈现;采用统一的全注意力机制,使每一帧视频的连接更加流畅,并实现主体的一致的多视点镜头切换;通过先进的图像和视频混合VAE(3D变分编码器),模型在细节表现上有显着的提升,尤其是高速镜头这样的场景。
据了解,腾讯的混合视频生成模式可应用于工业级业务场景,例如广告、动画制作、创意视频生成等场景。此前,已有多家媒体在内测阶段率先使用腾讯混元视频生成能力进行创意视频制作,产出了《祖国如此美丽》、《山水之间》等多部优秀作品。
混元系列大模型已全面开源
腾讯宣布开源大视频生成模型,已在Hugging Face平台和Github上发布。包含模型权重、推理代码、模型算法等完整模型,可供企业和个人开发者免费使用和开发生态插件。
基于腾讯混元的开源模型,开发者和企业无需从头开始训练,可以直接使用其进行推理,并可以基于腾讯混元系列创建专属应用和服务,可以节省大量人力和算力,加快人工智能的步伐。产业创新。
记者发现,大型模型开源后,可以吸引全球开发者参与模型的改进和优化,推动技术快速发展。国内外很多大型模型都宣布开源。比如美国知名企业家埃隆·马斯克旗下的人工智能初创公司xAI的大模型Grok,今年3月正式宣布开源,引起轰动。
今年以来,腾讯混元系列机型的开源速度不断加快。此前,腾讯混元已开源其文声文、文声图以及3D生成大模型。至此,腾讯混元系列大型模型已全面开源。









发表评论
◎欢迎参与讨论,请在这里发表您的看法、交流您的观点。