

DeepSeek发布原生稀疏注意力机制NSA论文,优化长文本AI模型性能
NSA专为长文本培训和推理而设计。它可以使用动态分层稀疏策略和其他方法来通过优化现代硬件的优化设计在培训和推理过程中显着优化传统AI模型的性能,尤其是提高长篇小说的推理能力。 ,在确保性能的同时,它可以提高推理速度并有效降低培训前成本。
DeepSeek创始人Liang Wenfeng出现在本文的作者中,在作者中排名第二。


其他研究人员来自DeepSeek,北京大学和华盛顿大学,其中第一作者Jingyang Yuan(Yuan Jingyang)在他在DeepSeek实习期间完成了这项研究。
根据信息,元王目前是北京大学的硕士学生。他的研究领域包括大型语言模型(LLM)和人工智能在科学中的应用(AI for Science)。他是DeepSeek-V3技术报告的主要作者之一,并且还参与了DeepSeek-R1项目,该项目旨在通过增强学习来激发大型语言模型的推理能力。
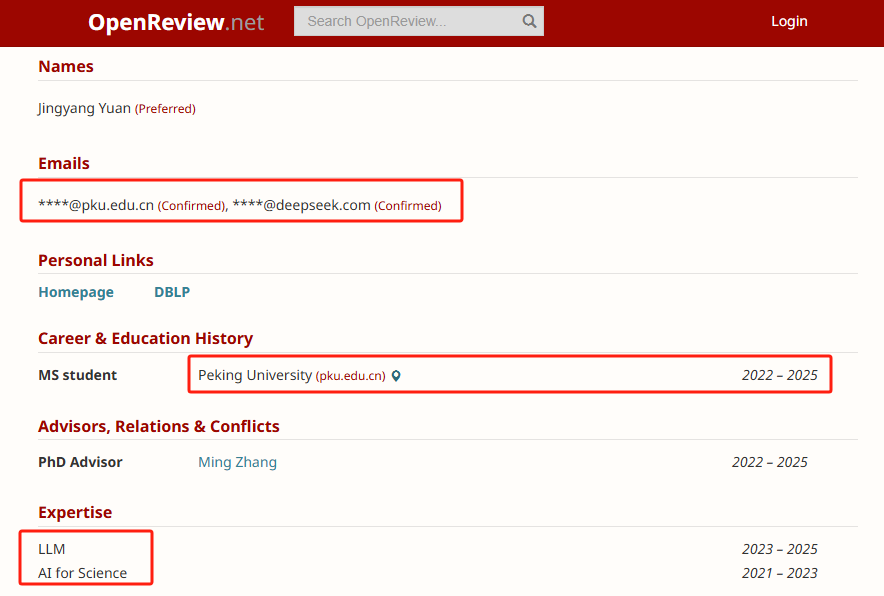
DeepSeek团队在本文中说,随着大语模型的发展,长上下文建模变得越来越重要,但是传统注意力机制的计算复杂性随着顺序长度的增加而增加了正方形,成为了一个约束,成为一个关键的瓶颈模型开发。
NSA是一种技术途径,旨在有效地处理长期文化任务,其核心创新在于:
1)动态分层稀疏策略:结合粗粒的令牌压缩和细粒的令牌选择,这不仅确保了全球环境感知,而且还考虑了本地信息的准确性。
2)硬件对齐和端到端培训:通过算法设计和算术强度平衡的硬件优化,计算速度得到了显着提高,同时支持端到端培训以减少训练预算的量。
实验表明,NSA不仅在一般和长篇文章任务上都表现良好,而且还显示出在复杂任务(例如链条推理)中的强大潜力,并且推理速度也得到了加速。总的来说,基于基准的基准,长文本处理和基于指导的推理任务,NSA的性能可以达到甚至超过传统的全部注意力模型,该模型很少以具有成本效益的方式在培训阶段使用。稀疏性在训练和促进方案方面的速度取得了显着提高,尤其是在解码阶段,它的改善达到了11.6倍。
通过有效的长期处理功能,NSA使模型能够直接处理整个书籍,代码仓库或多轮对话(例如Qianlong客户服务方案),从而扩展了大型语言模型在文档分析,代码生成领域的应用,复杂的推理等边界。例如,Gemini 1.5 Pro证明了较长的上下文潜力,NSA可以进一步降低此类模型的培训和推理成本。









发表评论
◎欢迎参与讨论,请在这里发表您的看法、交流您的观点。