

A股视觉认知概念股午后大涨,豆包发布无需语言模型的VideoWorld视频生成实验模型
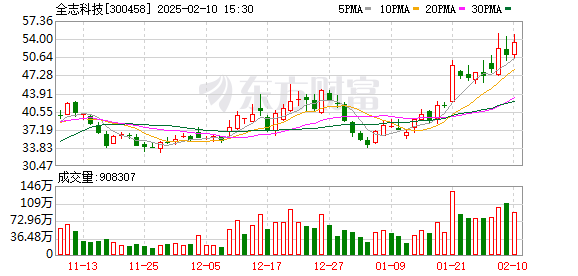
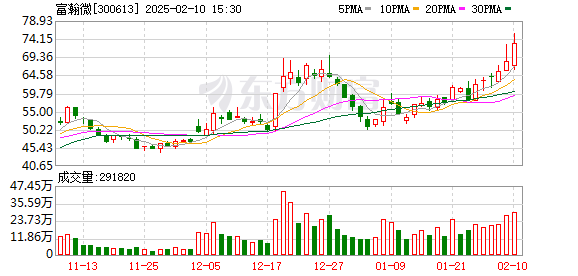
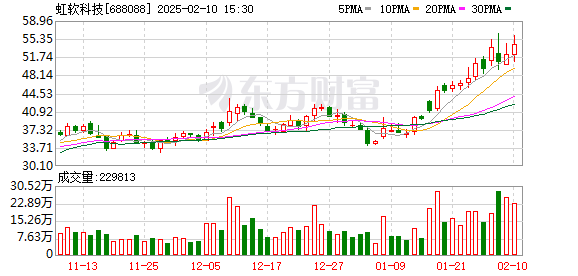
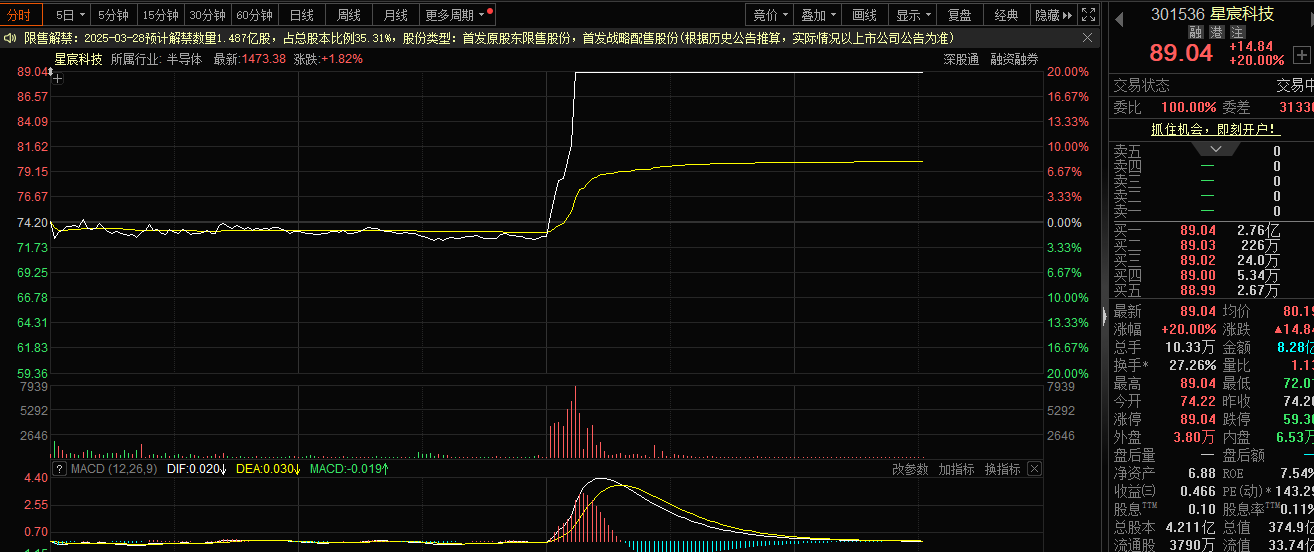
2月10日,A共享的视觉认知概念股票在下午急剧增强,Gem Xingchen Technology直接升至每日限制,而Quanzhi Technology,Fuhanwei,Hongruan Technology等人都急剧上升。
在新闻方面,Doubao发布了视频生成实验模型“ VideoWorld”。据报道,与Sora,Dall-E和Midjourney等主流多模型不同,VideoWorld在行业中首次实施了它不需要依赖语言模型。您可以通过“视觉信息”来理解世界。也就是说,VideoWorld可以通过浏览数据浏览视频,允许机器掌握复杂能力,例如推理,计划和决策。该团队的实验发现,VideoWorld仅使用300m参数实现了相当大的模型性能。
目前,项目的代码和模型是开源的。


大多数现有模型都依赖语言或标记数据学习知识,并且很少涉及纯视觉信号的学习。 Videoworld选择删除语言模型以实现理解和推理任务的统一执行。
它是如何完成的?
Doubao Mockup团队说,VideoWorld是基于潜在的动态模型(LDM),该模型可以有效地压缩视频帧之间的更改信息,同时保留丰富的视觉信息,从而压缩与关键决策和动作相关的视觉变化。显着提高知识学习的效率和有效性。
在不依靠任何强化学习搜索或奖励功能机制的情况下,Videoworld已达到专业的5阶段9x9 GO级别,并能够在各种环境中执行机器人任务。
但是,该模型并不完美,其在现实环境中的应用仍然面临着诸如高质量视频生成和多环境概括之类的挑战。这是最直观地反映出视频中有大量冗余信息的事实,这将极大地影响模型的学习效率,从而使视频序列的知识挖掘效率显着落后于文本形式,这就是不利于模型快速学习复杂的知识。
大型模型的视觉理解能力一直是AI的尖端研究方向之一。对于人类来说,“用眼睛看”是一种认知方法,其阈值比语言较低。正如Li Feifei教授在9年前的TED演讲中提到的那样,“孩子们可以不依靠语言理解现实世界。”
简而言之,AI视觉学习需要一个大型模型来了解对象/空格/场景的整体含义,并根据已识别的内容执行复杂的逻辑计算,并根据图像信息表达和更细致地创建并创建。
AI视觉学习能力的提高有望触发更多的AI应用程序。大城证券先前发布了一份研究报告,称国内AI模型的多模式能力正在继续改善。例如,诸如Kuaishou Keling AI模型和Bytedobao AI模型之类的视频生成的影响正在继续改善,包括精确的语义理解和一致性。多镜头生成,动态镜像等。从基本技术能力的升级中受益,国内AI应用程序继续进行迭代,而代币的呼叫继续增长,并且预计AI应用程序将从中受益。









发表评论
◎欢迎参与讨论,请在这里发表您的看法、交流您的观点。