

谷歌DeepMind研究员揭秘Qwen模型:超越OpenAI和DeepSeek的AI新星
换句话说,S1-32B在“巨人的肩膀”上,50美元的成本不能涵盖QWEN型号的培训成本。
问题2:超过OpenAI的O1和DeepSeek-R1是什么?
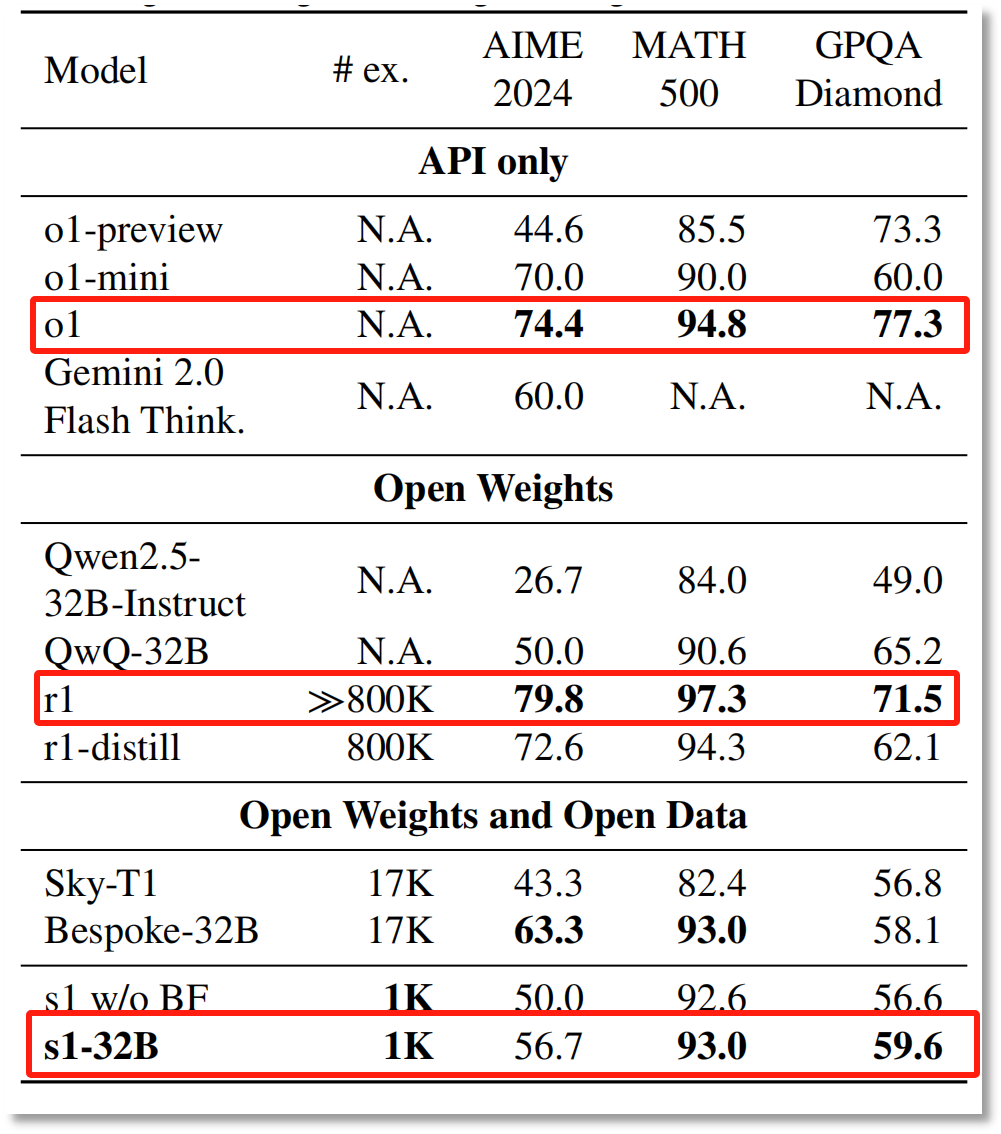
Li Feifei团队发表的论文提到,根据QWEN2.5-32B的QWEN2.5-32B-instruction在数学和编码能力测试中对S1-32B模型的性能进行了微调,与OpenAI的O1和DeepSeek的尖端推理模型相媲美R1。竞争数学问题的表现比O1-preiview高27%。
图像来源:纸质“ S1:简单的测试时间缩放”
此外,研究结果表明,S1-32B是具有最高样品效率的开放数据推断模型,其性能明显优于其基本模型(QWEN2.5-32B-Instruct)和OpenAI的推理模型O1-Preview。
实际上,S1-32B在特定的测试集上只能超过O1概述,并且不超过“全血” O1和DeepSeek-R1。
图像来源:纸质“ S1:简单的测试时间缩放”
研究结果表明,在AIME 2024和MATH 500中,S1-32B超过了O1-preview,但是无论哪种测试集,S1-32B均未超过“全血版本” O1官方版本DeepSeek-R1。
“烘焙价格”型号的背后
测试期间的扩展:使用更多的大脑并检查更多
实际上,Li Feifei论文的核心不是如何“汇总”模型价格,而是研究如何以最简单的方式实现“测试时间缩放”。
测试时间缩放是一种在模型推理阶段通过多步推断改善模型性能的技术。具体来说,通过强制性预算,研究团队控制了模型可以“思考”多长时间或多个步骤的时间或数个步骤。如果该模型过早地结束推理,则系统会鼓励模型延长思考时间,并确保其充分考虑问题。这意味着该模型将在推理时执行多个推理迭代,并逐渐优化推理结果,以最终产生高质量的答案。
例如,当被问及“ Raspberry”中的几个“ R”时,该模型首先执行初步推断,并提出错误的初步结果:有2 r。但是推理过程并没有结束,该模型重新提出了最后一个答案的结果,并输出了最终答案:3 r。

图像来源:纸质“ S1:简单的测试时间缩放”
OpenAI的O1系列模型是一个典型的例子,显示了测试过程中模型性能改进的潜力。
微软首席执行官萨蒂亚·纳德拉(Satya Nadella)曾经说过,我们正在目睹新的规模定律(缩放定律)的出现 - 该模型的效率与测试时间或推理时间计算有关。
高质量数据集S1K:数据炼金术
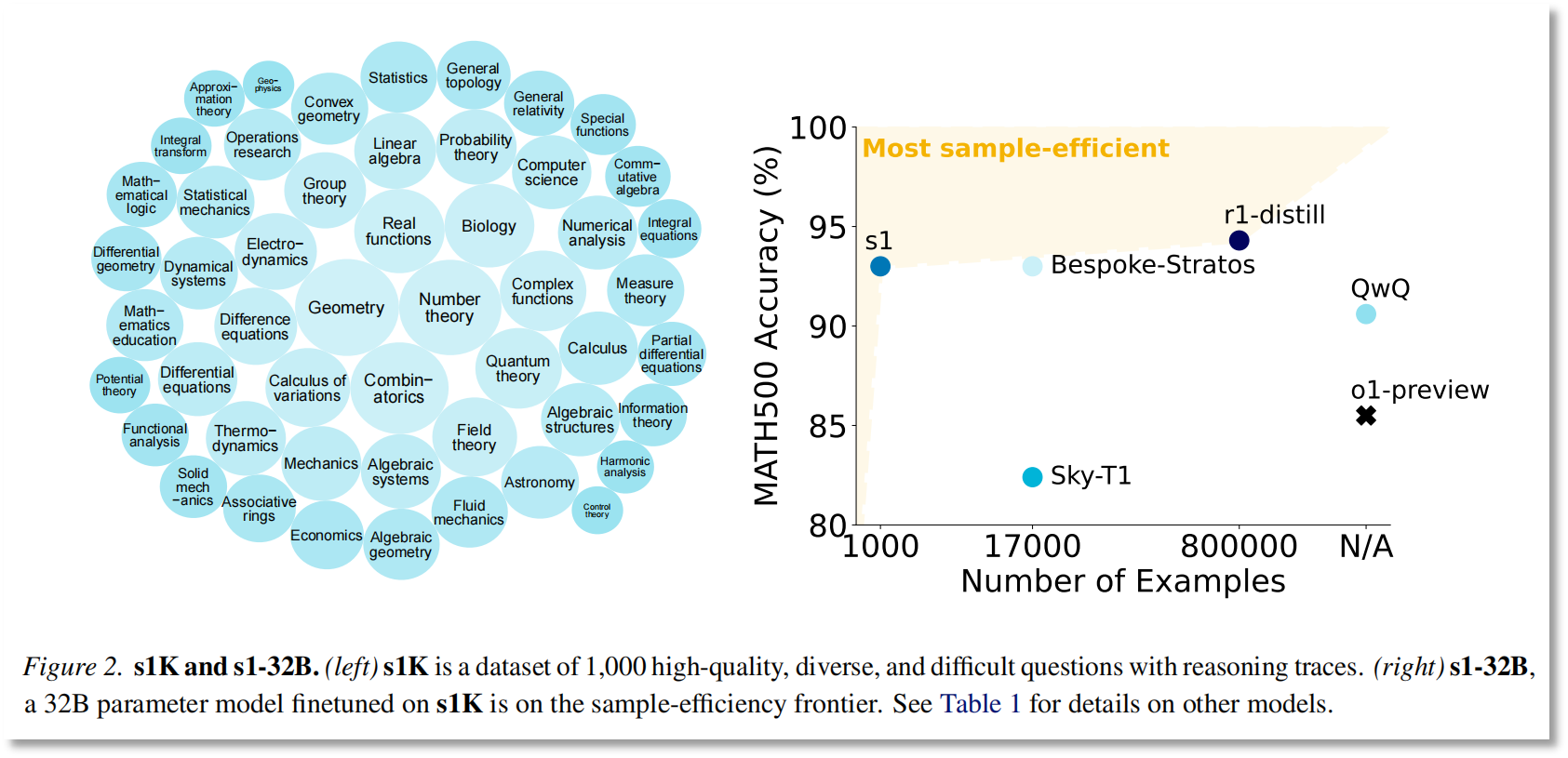
此外,Li Feifei的研究小组还收集了16个来源的59,029个高质量问题,包括数学竞赛问题,博士级的科学问题,奥运会竞争问题等,并通过三个标准进行了验证:难度,多样性和质量。
通过过滤,研究团队最终获得了一个包含1,000个样本的S1K数据集,其中涵盖了50个字段,例如几何,数字理论,量子力学等,每个问题都配备了Google Gemini 2.0 2.0 Flash将实验视为“教师模型”的闪光灯。蒸馏答案和推理轨迹。
该数据集建立在三个关键标准上:难度,多样性和质量。
高质量数据集大大降低了S1-32B模型的训练成本。
富丹大学计算机科学技术学院副教授兼博士生郑小树在接受《杂志》的记者采访时说,大规模数据可能不会成为每个人在下一步中竞争的战场,并且成本和产出之间的比率正在缓慢压缩,而高质量的数据将来将对微调和加强学习进行更多的投资。









发表评论
◎欢迎参与讨论,请在这里发表您的看法、交流您的观点。