

深度求索DeepSeek-V3横空出世:低成本预训练与高性能AI模型的突破
在此背后,DeepSeek-V3采用多头潜在注意力(MLA)进行高效推理,并采用DeepSeekMoE进行经济训练。研发团队已经证明,多令牌预测(MTP)有利于提高模型性能,可用于推理加速推测解码。在后训练方面,DeepSeek V3引入了一种创新方法,将推理能力从长思维链模型(DeepSeek R1)提炼到标准模型。这显着提高了推理性能,同时保持了 DeepSeek V3 的输出样式和长度控制。
有人认为,DeepSeek-V3极低的训练成本可能预示着大型AI模型的算力投资需求将大幅下降。甚至有人将27日A股算力概念的下跌与此联系起来。但也有人认为,虽然DeepSeek的性能出色,但其统计口径仅计算预训练,数据比例需要大量的预实验。合成数据的生成和清理也需要计算能力。此外,训练成本的降低和效率的提高并不意味着对算力的需求会减少。这只意味着各大厂商能够以更具成本效益的方式探索车型的终极能力。
“最重要的是,我们正式进入了分布式推理时代。”在谈及DeepSeek-V3时,轻子AI创始人兼CEO贾扬清在推理方面指出,“单GPU机器的显存(80×8=640G)已经不可能容纳所有参数了。虽然可以更新大内存机器以适应模型,需要分布式推理来确保性能和未来的扩展。”
中信证券研报也指出,近期DeepSeek-V3的正式发布引起了AI行业的广泛关注。在保证模型能力的同时,极大提升了训练效率和推理速度。 DeepSeek新一代模型的发布,意味着AI大型模型的应用将逐渐变得更加普惠,助力AI应用的广泛落地。同时,训练效率将大幅提升,这也将有助于推理计算能力的需求增加。

▌AI行业的“下一件大事”?
“我们已经达到了数据的顶峰……AI预训练的时代无疑将结束。” OpenAI联合创始人、前首席科学家Ilya Sutskever不久前断言。
许多人工智能投资者、创始人和首席执行官在采访中表示,人工智能规模法则的好处正在逐渐下降。
AI行业CEO、研究人员和投资者,包括a16z合伙人Anjney Midha和微软CEO Satya Nadella都发表了新判断:我们正处于一个Scaling Law的新时代——“测试时间计算时代”,即“推理时代” ”。这种能力让AI模型在回答问题之前有更多的时间和计算能力进行“思考”。 “这特别有希望成为下一件大事。”
▌AI应用兴起呼唤推理算力
为什么推理如此重要?
除了“旧版缩放定律”效应衰减之外,另一个原因在于AI应用——英伟达的竞争对手、AI芯片制造商Cerebras曾解释道,“快速推理是解锁下一代AI应用的关键。从语音到语音到视频,通过快速推理,以前无法实现的响应式智能应用程序将成为可能。”
以最近流行的豆包为例。不久前,豆宝家族全面更新,大豆宝模型的应用场景不断拓展。民生证券指出,这导致推理算力需求持续上升,主要集中在硬件设备算力需求、数据中心规模扩张需求和通信网络需求。
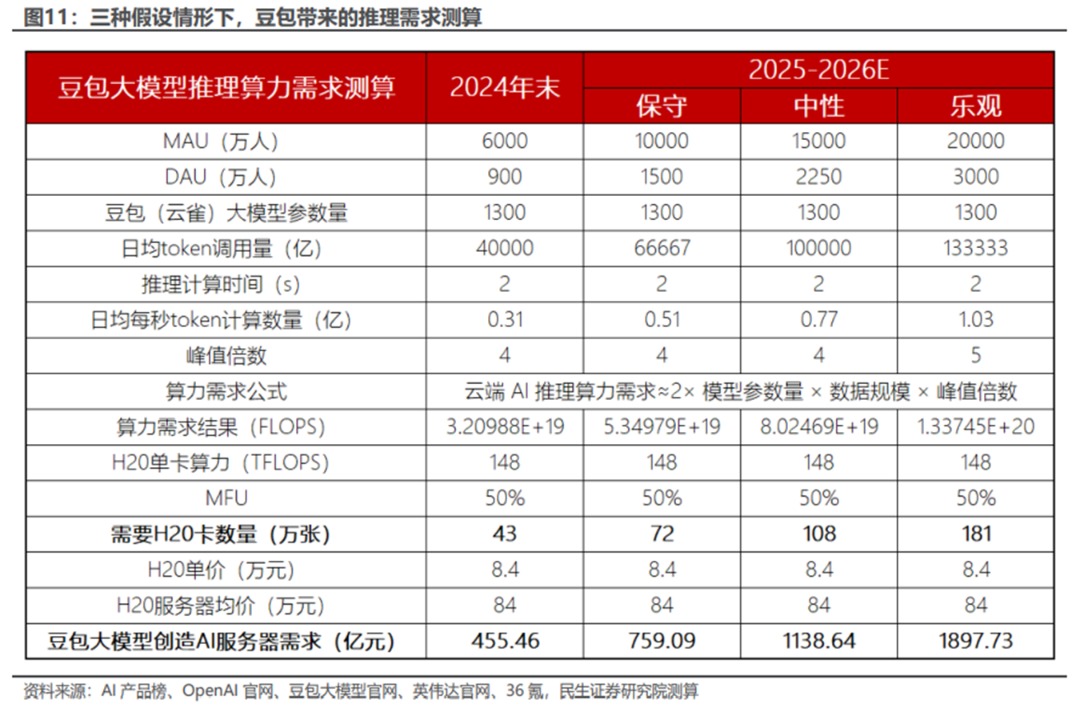
具体来说,豆宝大模型会给推理侧带来多少算力需求增量?分析师根据豆宝目前的月活跃用户数、日活跃用户数、日均调用量,做出了保守、中性、乐观三种假设。预计大豆宝模式可能带来的AI服务器资本分别为75.9、113.9、1898亿元。支出要求。
随着AI应用显着带动算力建设,分析人士指出,字节算力的资本支出持续上升。
此外,上周有报道称,小米正在打造自己的GPU万卡集群,并将大力投资大型AI模型。小米大模型团队成立时已经拥有6500颗GPU资源。
当然,字节跳动和小米并不孤单。海外科技巨头也在增加资本支出。据摩根士丹利预计,海外四大科技巨头2025年的资本支出可能高达3000亿美元,其中亚马逊964亿美元、微软899亿美元、Alphabet 626亿美元、Alphabet 523亿美元。对于元。
虽然目前还不清楚有多少资金将用于打造AI算力,但从这些巨头此前的各种表态以及近年来的资本走向可以想象,AI的占比不会太低。
Bloomberg Intelligence 最近的一份报告显示,企业客户可能会在 2025 年进行更大的 AI 投资,AI 支出增长将更加集中在推理端,以实现投资变现或提高生产率。
随着端侧AI体量的不断增加,以及豆宝、ChatGPT等AI应用的快速发展,多家券商研究报告指出,对算力的需求将从预训练加速向推理端转移。推理有望接力训练,成为下一阶段算力需求的主要来源。推动力。
a16z合伙人Anjney Midha表示,如果推理计算成为下一个扩展AI模型性能的领域,那么专用于高速推理的AI芯片的需求可能会大幅增加。如果找到答案与训练模型一样需要大量计算,那么人工智能中的恶霸将再次获胜。









发表评论
◎欢迎参与讨论,请在这里发表您的看法、交流您的观点。