

阿里巴巴发布通义千问Qwen2.5-Omni多模态模型,支持文本图像音频视频处理
![K图 09988_0]](http://news.lianzhou.cn/zb_users/upload/2025/27/1743042048888_0.png)
在周四清晨,北京时间,阿里巴巴发布了Tongyi Qianwen系列Qwen2.5-Omni的最新旗舰模型。该端到端的多模型为广泛的多模式感知而设计,能够处理各种输入,包括文本,图像,音频和视频,同时通过生成的文本和合成的语音提供实时流媒体响应。
根据“ Tongyi Qianwen Qwen”的官方微信帐户,该模型的主要特征如下:
全方位创新体系结构:QWEN团队提出了一个新的思想家 - 谈话架构,这是一种端到端的多模式模型,旨在支持对文本/图像/音频/视频的跨模式理解,同时流式传输文本和自然语音响应。 QWEN提出了一种称为TMROPE(时期一致的多模式绳)的新位置编码技术,该技术通过时轴对齐实现了视频和音频输入的准确同步。
实时音频和视频交互:架构旨在支持完整的实时互动,支持块的输入和即时输出。
自然和平稳的语音产生:就语音产生的性质和稳定性而言,超越了许多现有的流媒体和非流式替代方案。
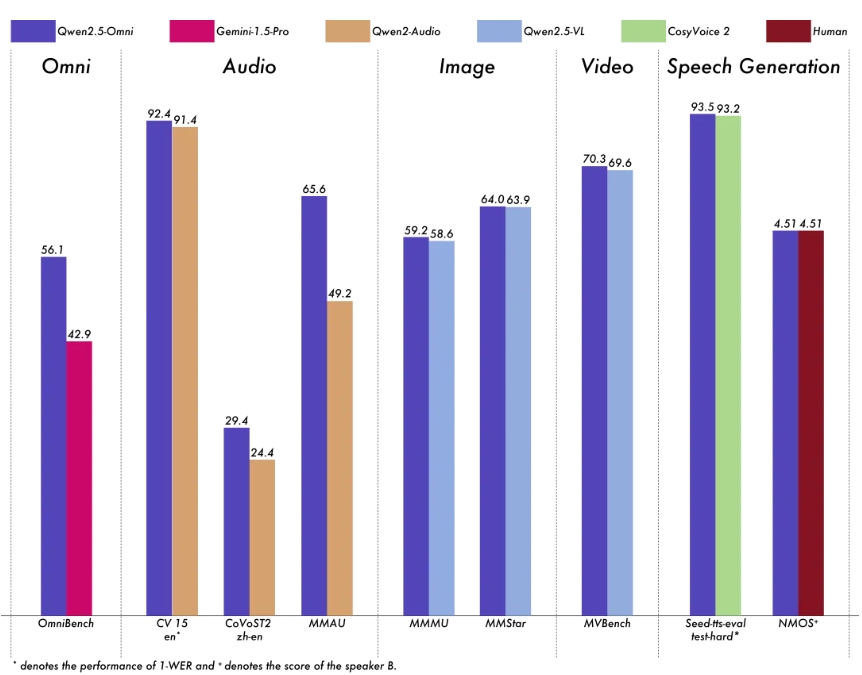
全模式性能优势:在基准相同尺度的单模模型时出色的性能。 Qwen2.5-omni比音频功能相似的Qwen2-audio好,并且与QWEN2.5-VL-7B相同。
出色的端到端语音命令随访:qwen2.5-omni在端到端语音命令后续措施中显示出与文本输入处理的可比效果,并在MMLU一般知识理解和GSM8K数学推理等基准中表现出色。
在模型性能方面,QWEN2.5-OMNI在各种模式下的单模模型和封闭源模型的单模模型的性能更好,包括图像,音频,音频和视频,例如QWEN2.5-VL-7B,QWEN2-AUDIO和GEMINI-1.5-PRO。
在多模式任务Omnibench中,QWEN2.5-OMNI达到了SOTA性能。此外,在单模式任务中,QWEN2.5-OMNI在多个领域中表现良好,包括语音识别(常见语音),翻译(Covost2),音频理解(MMAU),图像推理(MMMU,MMSU,MMSU,MMSU,MMSU),视频理解(MVBENCE)和语音产生(SEED-TTS-TTS-EVAL和主题自然听力)。
该模型现在是拥抱面,Modelscope,Dashscope和Github的开源。










发表评论
◎欢迎参与讨论,请在这里发表您的看法、交流您的观点。